발전기금
발전기금








[연구] 신동군 교수 연구실, AAAI Conference on Artificial Intelligence 2024 (AAAI-24)에 논문 1편 게재 승인
- 소프트웨어융합대학
- 조회수1196
- 2023-12-22

Intelligent Embedded Systems Laboratory (지도교수: 신동군)의 논문 1편이 인공지능 분야의 우수 학술대회인 AAAI Conference on Artificial Intelligence 2024 (AAAI-24)에 게재 승인되었습니다
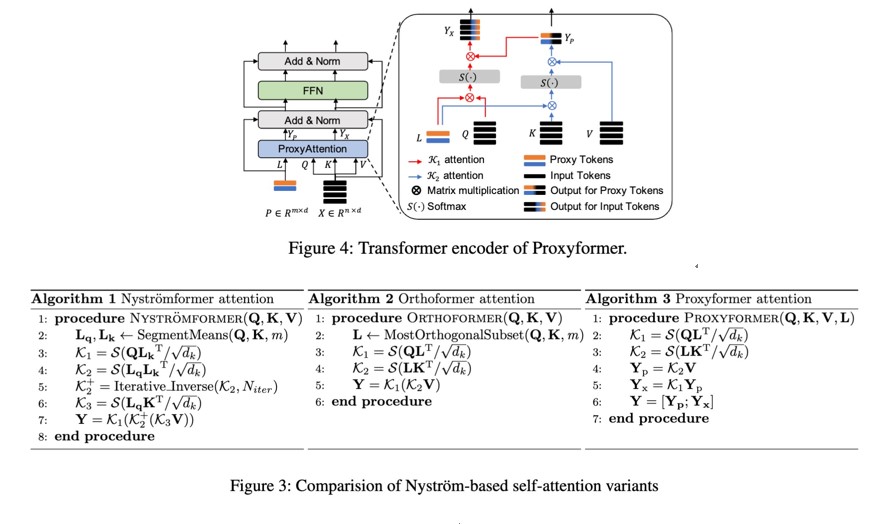
논문 #1: Proxyformer: Nystrom-Based Linear Transformer with Trainable Proxy Tokens
(인공지능학과 석사과정 이상호, 전기전자컴퓨터공학과 박사과정 이하윤)
"Proxyformer: Nystrom-Based Linear Transformer with Trainable Proxy Tokens" 논문은 selfattention 연산의 복잡도 문제에 초점을 맞추고 있습니다.. 이 논문에서는 기존 self-attention 연산 의 입력 시퀀스 길이 n에 대한 2차 복잡도를 해결하기 위해, Nystrom 방법과 신경 메모리(neural memory)를 통합하여 확장된 Nystrom attention 방식을 제안합니다. 첫째로 Nystrom 방법의 랜드 마크로 활용되는 학습 가능한 proxy token을 도입함으로써, attention 연산의 복잡도를 제곱에서 선형으로 줄이며, 입력 시퀀스를 고려한 랜드마크를 효과적으로 생성할 수 있도록 하였습니다. 둘 째로, 랜드마크 간 대조 학습(Contrastive Learning) 적용함으로써 최소한의 랜드마크를 사용하여 attention 맵을 효과적으로 복원할 수 있도록 학습하였습니다. 셋째로, 분해된 attention 행렬에 적 합한 dropout 방법을 개발하여, proxy token들이 효과적으로 학습되는 정규화를 가능하게 하였습 니다. 제안된 Proxyformer는 최소한의 proxy token으로 attention 맵을 효과적으로 근사할 수 있 게 되었으며, 이는 LRA 벤치마크에서 기존 기법들에 비해 우수한 성능을 보여주며 기존 selfattention 방식에 비해 4096 길이의 입력 시퀀스에서 3.8배 높은 처리량과 0.08배 낮은 메모리 사 용량을 달성하는 결과를 보여주었습니다.
[논문 #1 정보]
Proxyformer: Nystrom-Based Linear Transformer with Trainable Proxy Tokens
Sangho Lee, Hayun Lee, Dongkun Shin
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024
Transformer-based models have demonstrated remarkable performance in various domains, including natural language processing, image processing and generative modeling. The most significant contributor to the successful performance of Transformer models is the self-attention mechanism, which allows for a comprehensive understanding of the interactions between tokens in the input sequence. However, there is a well-known scalability issue, the quadratic dependency of self-attention operations on the input sequence length n, making the handling of lengthy sequences challenging. To address this limitation, there has been a surge of research on efficient transformers, aiming to alleviate the quadratic dependency on the input sequence length. Among these, the Nyströmformer, which utilizes the Nyström method to decompose the attention matrix, achieves superior performance in both accuracy and throughput. However, its landmark selection exhibits redundancy, and the model incurs computational overhead when calculating the pseudo-inverse matrix. We propose a novel Nyström method-based transformer, called Proxyformer. Unlike the traditional approach of selecting landmarks from input tokens, the Proxyformer utilizes trainable neural memory, called proxy tokens, for landmarks. By integrating contrastive learning, input injection, and a specialized dropout for the decomposed matrix, Proxyformer achieves top-tier performance for long sequence tasks in the Long Range Arena benchmark.