 발전기금
발전기금








-

- [연구] 보안공학 연구실, DSN 2021 컨퍼런스 논문 게재
- 보안공학 연구실 전자전기컴퓨터공학과 김베드로 학생(박사과정: 제1저자), 김형식(교신저자)가 작성한 "Decamouflage: A Framework to Detect Image-Scaling Attacks on CNN" 논문이 dependability와 security 분야 top conference인 DSN (IEEE/IFIP International Conference on Dependable Systems and Networks) 2021 컨퍼런스에서 발표될 예정입니다. 본 연구에서는 Image scaling attack (이미지 변조 공격)을 탐지할 수 있는 프레임워크를 제안하였습니다. Image scaling attack은 USENIX Security 2019에서 처음으로 소개된 공격으로 공격자에 의해 변조된 이미지(정상 이미지처럼 보이지만, 공격 이미지가 숨어있음)가 시스템에 입력되기 전 거치는 Pre-processing 과정에 특정 사이즈로 다운사이즈 되면 공격 이미지로 보여지는 취약점을 이용한 것이다. 본 연구에서는 이를 탐지하기 위해 이미지 유사도 비교방식에 기반한 탐지 방식을 소개합니다. 제안된 방식들은 Image scaling 공격에 대한 효과적인 탐지 성능을 보였으며, white box와 black box scenario에서 탐지 성능을 측정 및 분석을 통해 그 성능을 검증하였습니다. 본 논문은 글로벌 핵심인력 양성 사업의 일환으로 호주 CSIRO Data61과 공동 연구가 진행되었습니다. [논문 정보] Decamouflage: A Framework to Detect Image-Scaling Attacks on CNN IEEE/IFIP International Conference on Dependable Systems and Networks (DSN) 2021 Abstract: Image-scaling is a typical operation that processes the input image before feeding it into convolutional neural network models. However, it is vulnerable to the newly revealed image-scaling attack. This work presents an image-scaling attack detection framework, Decamouflage, consisting of three independent detection methods: scaling, filtering, and steganalysis, to detect the attack through examining distinct image characteristics. Decamouflage has a pre-determined detection threshold that is generic. More precisely, as we have validated, the threshold determined from one dataset is also applicable to other different datasets. Extensive experiments show that Decamouflage achieves detection accuracy of 99.9% and 99.8% in the white-box and the black-box settings, respectively. We also measured its running time overhead on a PC with an Intel i5 CPU and 8GB RAM. The experimental results show that image-scaling attacks can be detected in milliseconds. Moreover, Decamouflage is highly robust against adaptive image-scaling attacks (e.g., attack image size variances).
-
- 작성일 2021-04-09
- 조회수 1137
-
_CVPR_2021_논문그림2.PNG)
- [연구] 허재필 교수 연구실, 현상익 석사과정, 김지환 박사과정 CVPR 2021 국제학술대회 논문 게재
- 비주얼컴퓨팅연구실(지도교수: 허재필)의 현상익 학우(인공지능학과 석사과정)와 김지환 학우(인공지능학과 박사과정)가 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021에 “Self-Supervised Video GANs: Learning for Appearance Consistency and Motion Coherency” 논문을 게재하였습니다. CVPR는 컴퓨터 비전 및 인공지능 분야의 Top-tier 학술대회이며, 2021년에는 온라인으로 개최됩니다. 본 연구에서는 비디오를 생성하는 적대적신경망(Generative Adversarial Networks, GANs)의 성능 향상을 위한 자가학습(Self-Supervised Learning) 기술을 제시하였습니다. 비디오 컨텐츠를 영상의 모습(Appearance)과 움직임(Motion)의 조합으로 정의하고, 모습 및 움직임의 일관성을 가진 자연스러운 비디오 생성을 위해 각각의 성분에 대한 자가학습목표(Self-supervision Objective)를 모델링 하였습니다. 제안된 모델(SVGAN)은 현재 비디오 생성 분야에서 가장 높은 성능을 달성하였으며, 현재 이미지 생성에 집중되어 있는 GAN 연구가 비디오 도메인으로 확장될 수 있도록 하는 밑거름이 될 것입니다. [논문 정보] Self-Supervised Video GANs: Learning for Appearance Consistency and Motion Coherency Sangeek Hyun, Jihwan Kim, and Jae-Pil Heo IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 Abstract: A video can be represented by the composition of appearance and motion. Appearance (or content) expresses the information invariant throughout time, and motion describes the time-variant movement. Here, we propose selfsupervised approaches for video Generative Adversarial Networks (GANs) to achieve the appearance consistency and motion coherency in videos. Specifically, the dual discriminators for image and video individually learn to solve their own pretext tasks; appearance contrastive learning and temporal structure puzzle. The proposed tasks enable the discriminators to learn representations of appearance and temporal context, and force the generator to synthesize videos with consistent appearance and natural flow of motions. Extensive experiments in facial expression and human action public benchmarks show that our method outperforms the state-of-the-art video GANs. Moreover, consistent improvements regardless of the architecture of video GANs confirm that our framework is generic.
-
- 작성일 2021-04-06
- 조회수 1528
-
- [연구] 데이터 지능 및 학습 연구실(지도교수: 이종욱 교수) 웹 정보 검색 및 자연어 처리 분야 저명한 국제 학술대회(WSDM, WWW, NAACL)에 3편의 논문 게재
- 데이터 지능 및 학습 연구실(지도교수: 이종욱 교수) 웹 정보 검색 및 자연어 처리 분야 저명한 국제 학술대회(WSDM, WWW, NAACL)에 3편의 논문 게재 1. Minjin choi, Yoonki Jeong, Joonseok Lee, Jongwuk Lee, “Local Collaborative Autoencoders” ACM International Conference on Web Search and Data Mining (WSDM), 2021 2. Minjin choi, Jinhong Kim, Joonseok Lee, Hyunjung Shim, Jongwuk Lee, “Session-aware Linear Item-Item Models for Session-based Recommendation” The Web Conference (WWW), 2021 3. Minjin choi, Sunkyung Lee, Eunseong Choi, Heesoo Park, Junhyuk Lee, Dongwon Lee, Jongwuk Lee, “MelBERT: Metaphor Detection via Contextualized Late Interaction using Metaphorical Identification Theories,” Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2021 참여 연구원 명단 최민진, 정윤기, 김진홍, 이선경, 최은성 (왼쪽부터) 1. 사용자 선호도의 지역적 특성을 고려한 추천 모델 개발 (WSDM 2021). 추천 모델은 사용자의 숨겨진 선호도를 추론하여 사용자가 선호하는 소량의 정보를 효과적으로 제공하기 위한 학습 모델을 의미한다. 최근 연구되는 많은 수의 추천 모델은 사용자간 유사한 평점 패턴을 기반으로 추천 결과를 제공하는 협업 필터링을 기반으로 하고 있다. 본 연구진은 기존의 협업 필터링 모델이 모든 사용자의 패턴을 고려하여 학습하기에 특정 사용자의 선호도를 효과적으로 파악하는데 어려움이 있음을 발견하고, 이를 개선하기 위해 지역적 패턴을 고려하여 학습할 수 있는 방법을 제안하였다. 제안 방법을 통해 기존 추천 모델 대비 정확도가 7.95%까지 개선될 수 있음을 확인하였다. 2. 선형 기반 세션 추천 모델 개발 (WWW 2021). 최근 주목을 받고 있는 세션 기반 추천 모델은 (1) 사용자의 정보를 요구하지 않으면서 (2) 특정 세션 내에서 사용자의 숨겨진 선호도를 파악하여 추천 결과를 제공하는 것을 목적으로 한다 (아래 그림 참고). 이와 같은 방식은 사용자 정보를 요구하지 않아 범용적으로 활용성이 높은 장점이 있으나, 기존의 추천 모델 대비 데이터의 희소성이 대폭 증가하여 정확도를 높이기 어려운 단점이 있다. 또한, 실시간으로 결과를 빠르게 제공해야 하는 추천 시스템의 제약 조건도 함께 고려되어야 한다. 본 연구진은 이와 같은 문제를 해결하기 위해 항목 간 관련성을 효과적으로 파악할 수 있는 세션 기반 선형 모델을 제안하였다. 제안 모델은 기존의 많은 학습 파라미터를 통해 정확도를 개선하고자 하는 심층 신경망 기반 추천 모델 대비 파라미터 수가 적고 계산이 간단하기 때문에 빠른 학습 시간과 추론 시간을 보인다. 더하여, 기존의 심층 신경망 모델과 비슷한 추천 정확도를 보임을 확인할 수 있었다 3. BERT 기반 은유 탐지 모델 개발 (NAACL 2021). 은유는 특정 단어에 대해서 행동, 개념 및 물체 등을 유사한 성질을 가진 다른 말로 대체해서 사용하는 비유법 중 하나로 인간의 고차원적인 언어 사용 방법을 의미한다. 예를 들어 “발레리나가 백조 같다.” 고 표현하였을 때, 백조의 의미는 사전의 의미의 동물을 의미하는 것이 아닌 우아한 행동을 비유한 것으로 해석할 수 있다. 본 연구진은 특정 문장에서 은유 표현을 담고 있는 단어를 분류하기 위한 모델을 개발하였으며, 은유 탐지를 위한 두 가지 언어학적 이론을 기반으로 최근 많이 활용되고 있는 언어 이해 모델 중 하나인 BERT에 접목하였다. 실험 결과, 제안 모델은 은유 탐지 분류의 정확도를 VUA 데이터셋에서 F1-Score를 기준으로 79.8%까지 달성함을 확인할 수 있었다.
-
- 작성일 2021-03-17
- 조회수 1391
-
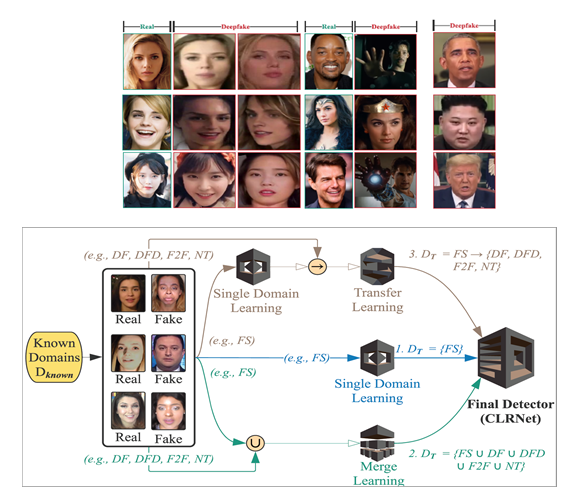
- [연구] 우사이먼성일 교수 연구실, Tariq Shahroz, 이상엽 박사과정 연구원 WWW 2021 국제 학술대회 논문 게재 확정
- [데이터 기반 인공지능 보안 연구실(DASH LAB) Tariq Shahroz, 이상엽 박사과정 연구원 WWW 2021 국제 학술대회 논문 게재 확정 지도교수: 우사이먼성일] DASH 연구실 소프트웨어학과Tariq Shahroz(박사과정연구원: 제1저자)와 이상엽(박사과정연구원: 제2저자), 우사이먼성일(교신저자)의 “One Detector to Rule Them All: Towards a General Deepfake Attack Detection Framework” 논문이 웹 및 데이터 마이닝 분야의 최우수국제 학술대회(BK IF=4)인 WWW (The Web Conference) 2021에 최종 논문 게재가 승인되었고 4월에 발표될 예정입니다. 본 연구에서는 사회적으로 큰 이슈가 되고 있는 딥페이크 가짜 동영상을 효율적으로 탐지할 수 있는 딥러닝 기반 알고리즘(Convoluional LSTM, Transfer Learning, Domain Adaptation)을 제안합니다. 특정인물을 다른 사람의 얼굴에 대입시켜 가짜 영상을 만드는 딥페이크 생성 기법은 날이 갈수록 다양해지고 있으며, 이에 대한 대응책이 필요한 상황입니다. 기존의 딥페이크 탐지 기법들은 다양한 생성기법을 한 번에 탐지하지 못하며, 각각의 생성 기법을 탐지하기 위해 방대한 양의 데이터와 학습 시간이 필요합니다. 이 경우 새로운 딥페이크 생성 기법이 발생한다면, 기존의 탐지 기법들은 탐지에 실패할 것입니다. 또한, 동영상을 프레임으로 나누어 각 프레임별 딥페이크 탐지를 진행하기 때문에, 동영상이 가진 시간적 특성을 전혀 고려하지 않습니다. 본 연구에서는 이를 해결하고 알려지지 않은 딥페이크에 더 잘 대처하기 위해, CLRNet(Convolutional LSTM-based Residual Network)을 개발하여 여러 딥페이크 생성 기법을 탐지하는 동시에 동영상의 시간적 특성을 모두 활용할 수 있는 딥러닝 탐지 알고리즘을 소개합니다. 제안된 모델은 비교 모델 대비 효과적인 성능 향상을 이뤘으며, 실제 온라인에서 유출 되어있는 영상을 통해 그 성능을 검증하였습니다. [논문] “One Detector to Rule Them All: Towards a General Deepfake Attack Detection Framework”, The Web Conference 2021 (WWW 2021) Deep learning-based video manipulation methods have become widely accessible to the masses. With little to no effort, people can quickly learn how to generate deepfake (DF) videos. In particular, females have been occasional victims of deepfake, which are widely spread on the Web. While deep learning-based detection methods have been proposed to identify specific types of DFs, their performance suffers for other types of deepfake methods, including real-world deepfakes, on which they are not sufficiently trained. In other words, most of the proposed deep learning-based detection methods lack transferability and generalizability. Beyond detecting a single type of DF from benchmark deepfake datasets, we focus on developing a generalized approach to detect multiple types of DFs, including deepfakes from unknown generation methods such as DeepFake-in-the-Wild (DFW) videos. To better cope with unknown and unseen deepfakes, we introduce a Convolutional LSTM-based Residual Network (CLRNet), which adopts a unique model training strategy and explores spatial as well as the temporal information in a deepfakes. Through extensive experiments, we show that existing defense methods are not ready for real-world deployment. Whereas our defense method (CLRNet) achieves far better generalization when detecting various benchmark deepfake methods (97.57% on average). Furthermore, we evaluate our approach with a high-quality DeepFake-in-the-Wild dataset, collected from the Internet containing numerous videos and having more than 150,000 frames. Our CLRNet model demonstrated that it generalizes well against high-quality DFW videos by achieving 93.86% detection accuracy, outperforming existing state-of-the-art defense methods by a considerable margin.
-
- 작성일 2021-01-25
- 조회수 1477
-

- [연구] 우사이먼성일 교수 연구실(DASH Lab) , 2020 인공지능 그랜드 챌린지 행동인지 트랙 3위
- [데이터 기반 인공지능 보안 연구실(DASH LAB) 2020 인공지능 그랜드 챌린지 행동인지 트랙 3위 지도교수: 우사이먼성일] 소프트웨어대학 우사이먼 교수 연구팀(DASH Lab: https://dash-lab.github.io, 이한빈(인공지능학과석사 과정), 강준형(인공지능학과 석사과정), 김준엽(소프트웨어학과 석사과정), 김민하(소프트웨어학과 석사과정), 안재주(소프트웨어학과 석사과정/융합보안트랙) 및 김정호(소프트웨어학과 학사과정), 김진범(소프트웨어학과 학사과정), 김유현(소프트웨어학과 학사과정), 박건우(소프트웨어학과 석사과정))이 지난해 12월에 열린 과기정통부가 주관하고 정보통신기획평가원(IITP)에서 주최한 “2020 인공지능 그랜드 챌린지 2단계 대회” 행동인지 트랙에서 3위를 수상하며 정보통신기획평가원장상과 후속 연구비를 지원받았다. “인공지능 그랜드 챌린지”대회는 제시된 문제를 해결하기 위해 참가자들이 개발한 딥러닝 알고리즘을 가지고 실력을 겨루는 도전 경쟁형 연구개발(R&D) 경진대회이다. 우사이먼 교수 연구팀은 행동인지 트랙에 참가하였고, 지난해 7월 열린 1단계 대회 우승(1위)에 이어 금번 대회에서도 3위를 수상함으로써 실시간 객체 탐지 및 이상 행동 탐지에 대한 기술력을 다시 한번 인정받았다.
-
- 작성일 2021-01-21
- 조회수 1576
-

- [연구] 고영중 교수 연구실, 김기환 연구원 EACL 2021 국제 학술대회 논문 게재
- 고영중 교수 연구실, 김기환 연구원 EACL 2021 국제 학술대회 논문 게재 [자연어처리 연구실(NLP Lab)] 김기환 연구원 EACL 2021 국제 학술대회 논문 게재 지도교수: 고영중 교수 자연어처리 연구실 김기환 연구원의 “Graph-based Fake News Detection using a Summarization Technique” 논문이 자연어처리 분야의 top-tier 국제 학술대회인 EACL (Conference of the European Chapter of the Association for Computational Linguistics) 2021에 최종 논문 게재가 승인되었고 4월에 발표될 예정입니다. 본 연구에서는 문서 내용이 진실을 말하고 있는지 가짜 내용을 말하고 있는지 분류하는 Fake News Classification 문제를 해결하기 위해 Graph와 Summarization 기법을 사용한 방법을 제안합니다. 기존의 Fake News Detection 방법은 문서의 정확한 주제를 파악하지 않고 문서 내 문장 사이의 관계를 정확하게 파악하지 않는 문제가 있습니다. 본 연구에서는 이를 해결하기 위해 요약 기법 (Summarization Technique)을 사용해 문서의 주제를 정확하게 파악하고 문장 사이의 관계를 그래프 구조 (Graph Structure)로 표현하여 문서 내 내용을 정확하게 파악하는 방법을 제시하였습니다. 제안된 모델은 비교 모델 대비 효과적인 성능 향상을 이뤘습니다. [논문] “Graph-based Fake News Detection using a Summarization Technique”, The 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021. Abstract: Nowadays, fake news is spreading in various ways, and this fake information is causing a lot of social damages. Thus the need to detect fake information is increasing to prevent the damages caused by fake news. In this paper, we propose a novel graph-based fake news detection method using a summarization technique that uses only the document internal information. Our proposed method represents the relationship between all sentences using a graph and the reflection rate of contextual information among sentences is computed by using an attention mechanism. In addition, we improve the performance of fake news detection by utilizing summary information as an important subject of the document. The experimental results demonstrate that our method achieves high accuracy, 91.04%, that is 8.85%p better than the previous method.
-
- 작성일 2021-01-15
- 조회수 1093
-

- [연구] [CSI 네트워킹 시스템 연구실] 정찬규 연구원 INFOCOM 2021 국제 학술대회 논문 게재
- CSI Lab ( Computer Systems and Intelligence Lab ) 의 네트워킹 시스템 연구실 정찬규 연구원의 "GPU-Ether: GPU-native Packet I/O for GPU Applications on Commodity Ethernet" 논문이 컴퓨터 네트워킹 분야의 top-tier 국제 학술대회인 IEEE INFOCOM 2021 에 최종 논문 게재가 승인되었고 내년 5월에 발표될 예정입니다. 본 논문은 정찬규 박사과정( 전자전기컴퓨터공학과 )과 김수환 학사과정 ( 수학과 ) 이 1, 2 저자로 참여하고, CSI Lab의 염익준교수, 우홍욱 교수가 3,4 저자로 참여하고, 김영훈 교수가 교신저자로 참여하였습니다. 본 연구에서는 상용 이더넷 환경에서도 GPU를 위한 고성능 네트워킹이 가능하도록 하는 GPU-Ether를 제안합니다. 현재 데이터 센터 일부 및 HPC ( High Performance Computing ) 환경에서는 RDMA 나 NetFPGA, SmartNIC 등의 비싼 전용 네트워크 장비를 활용한 GPU-Direct Networking 이 지원되나, 아직까지 대부분의 데이터 센터 및 클라우드 환경에서 사용되는 일반적인 상용 이더넷 장비에서는 이러한 최적화가 진행되지 않은 점에 착안 본 연구를 진행하였습니다. 본 연구진은 인텔 사의 Intel 10GbE X520-DA2 NIC 과 Nvidia 사의 Quadro P4000 GPU를 활용해 GPU-native Packet I/O 프로토타입을 구현했고, 다양한 네트워크 어플리케이션들 (소프트웨어 라우터, IPSec Gateway, NIDS)을 추가로 구현하여 성능을 검증하였습니다. IEEE INFOCOM 2021: https://infocom2021.ieee-infocom.org/ CSI Lab: http://csi.skku.edu 김영훈 교수님 교수실: 23111 CSI Lab. 네트워킹 시스템 연구실 | http://csi.skku.edu
-
- 작성일 2020-12-18
- 조회수 1510
-

- [연구] 김형식교수, 2021 ICSE 논문 게재 승인
- 보안공학 김형식 교수의 “Fine with ``1234''? An Analysis of SMS One-Time Password Randomness in Android Apps” 논문이 소프트웨어 공학 분야의 top-tier 국제 학술대회인 ICSE (The 43rd International Conference on Software Engineering), 2021에 최종 논문 게재가 승인되었고 내년 5월에 발표될 예정입니다. 본 연구는 안드로이드 앱에서 사용하는 OTP 생성 번호에서 안전 하지 않은 난수 생성 함수를 탐지하는 연구로서 실험을 진행한 OTP를 현재 사용하고 있는 6431개의 안드로이드 앱를 제안 도구(OTP-Lint)를 이용하여 분석한 결과, 399개의 앱에서 취약한 난수 생성 함수를 이용하여 OTP를 사용하고 있다는 사실을 밝혀냈습니다. 본 연구는 김형식 교수가 호주의 CSIRO Data61에서 방문 연구원으로 재직하는 동안 수행한 연구 결과입니다. [Abstract] A fundamental premise of SMS One-Time Password (OTP) is that the used pseudo-random numbers (PRNs) are uniquely unpredictable for each login session. Hence, the process of generating PRNs is the most critical step in the OTP authentication. An improper implementation of the pseudo-random number generator (PRNG) will result in predictable or even static OTP values, making them vulnerable to potential attacks. In this paper, we present a vulnerability study against PRNGs implemented for Android apps. A key challenge is that PRNGs are typically implemented on the server-side, and thus the source code is not accessible. To resolve this issue, we build an analysis tool, OTP-Lint, to assess implementations of the PRNGs in an automated manner without the source code requirement. Through reverse engineering, OTP-Lint identifies the apps using SMS OTP and triggers each app's login functionality to retrieve OTP values. It further assesses the randomness of the OTP values to identify vulnerable PRNGs. By analyzing 6,431 commercially used Android apps downloaded from Google Play and Tencent Myapp, OTP-Lint identified 399 vulnerable apps that generate predictable OTP values. Even worse, 194 vulnerable apps use the OTP authentication alone without any additional security mechanisms, leading to insecure authentication against guessing attacks and replay attacks.
-
- 작성일 2020-12-16
- 조회수 1185
-

- [연구] [실시간 컴퓨팅 연구실] IEEE RTSS 2020 국제 저명 학술대회 논문 발표
- 실시간 컴퓨팅 연구실(지도교수:이진규)에서는 실시간 시스템 분야에서 가장 저명한 국제 학술대회인 IEEE RTSS (Real-Time Systems Symposium) 2020에 아래의 논문을 발표하였습니다. [논문] "Non-Preemptive Real-Time Multiprocessor Scheduling Beyond Work-Conserving" 본 논문에서는 비선점형(Non-preemptive) 실시간 작업들의 실시간성 보장을 위해 체계적으로 프로세서를 휴식하는 counter-intuitive한 새로운 체제를 제시하여, 기존 기법으로는 불가능하였던 수많은 비선점형 실시간 작업들의 실시간성 보장을 가능하게 하였습니다. 본 논문은 실시간 컴퓨팅 연구실의 백형부 박사후 연구원(현 인천대학교 교수)과 석사과정 곽재헌 학생(현 KAIST 박사과정)이 1, 2저자로 참여하고, 이진규 교수가 교신저자로 참여하였습니다. 논문 다운로드: https://rtclskku.github.io/website/papers/IC202012BKL.pdf IEEE RTSS: http://2020.rtss.org 실시간 컴퓨팅 연구실: https://rtclskku.github.io/website/
-
- 작성일 2020-12-10
- 조회수 1142
-

- [연구] [자연어처리연구실] 김보성 연구원 AAAI 2021 국제 학술대회 논문 게재
- [자연어처리연구실] 김보성 연구원 AAAI 2021 국제 학술대회 논문 게재 지도교수: 고영중 교수 자연어처리 연구실 김보성 연구원의 “Commonsense Knowledge Augmentation for Low-Resource Languages via Adversarial Learning” 논문이 인공지능 분야의 top-tier 국제 학술대회인 AAAI Conference on Artificial Intelligence, 2021에 최종 논문 게재가 승인되었고 내년 2월에 발표될 예정입니다. 본 연구에서는 저자원(low-resource) 언어의 지식 데이터를 확장하는 적대적 학습(adversarial learning) 방법을 제안합니다. 기존 데이터 확장에서 사용되는 번역 방법은 모호성 문제가 발생하며 모델 학습 시 태깅 데이터가 필요하다는 한계점이 있습니다. 본 논문에서는 적대적 학습을 통해 모델이 언어 독립적인 특성을 학습하게 하고, 풍부한 영어 데이터로부터 저자원 언어의 지식을 자동으로 확장할 수 있는 방법을 제시합니다. 제안된 모델은 한국어 지식 데이터에서 93.7%의 정확도를 달성하였으며, 626,681개의 한국어 지식을 생성하였습니다. 또한 16개의 언어를 이용한 테스트에서 모두 효과적인 성능 향상을 이뤘습니다. [논문] “Commonsense Knowledge Augmentation for Low-Resource Languages via Adversarial Learning”, The 35th AAAI Conference on Artificial Intelligence, 2021. Abstract: Commonsense reasoning is one of the ultimate goals of artificial intelligence research because it simulates the human thinking process. However, most commonsense reasoning studies have focused on English because available commonsense knowledge for low-resource languages is scarce due to high construction costs. Translation is one of the typical methods for augmenting data for low-resource languages; however, translation entails ambiguity problems, where one word can be translated into multiple words due to polysemes and homonyms. Previous studies have suggested methods to measure the validity of translated multiple triples by using additional metadata and manually labeled data. However, such hand-crafted datasets are not available for many low-resource languages. In this paper, we propose a knowledge augmentation method using adversarial networks that does not require any labeled data. Our adversarial networks can transfer knowledge learned from a resource-rich language to low-resource languages and thus measure the validity score of translated triples even without labeled data. We designed experiments to demonstrate that high-scoring triples obtained by the proposed model can be considered augmented knowledge. The experimental results show that our proposed method for a low-resource language, Korean, achieved 93.7% precision@1 on a manually labeled benchmark. Furthermore, to verify our model for other low-resource languages, we introduced new test sets for knowledge validation in 16 different languages. Our adversarial model obtains strong results for all language test sets. We will release the augmented Korean knowledge and test sets for 16 languages. 고영중 교수: yjko@skku.edu, 자연어처리연구실: nlp.skku.edu; nlplab.skku.edu
-
- 작성일 2020-12-07
- 조회수 1230