 발전기금
발전기금








-

- [연구] 우사이먼 교수(DASH) 연구실 NeurIPS 2021 국제학술대회 논문 2편 게재 승인
- Data-driven AI Security HCI 연구실(지도교수: 우사이먼성일)의 논문 2편이 인공지능 및 기계학습 분야 최우수 학회인 Neural Information Processing System (NeurIPS) 2021 (BK CS IF=4)의 Datasets and Benchmarks Track 에 게재 승인되었습니다. 논문 #1: “VFP290K: A Large-Scale Benchmark Dataset for Vision-based Fallen Person Detection” (공동 1저자: 소프트웨어학과 석사과정 안재주, 인공지능학과 석사과정 김정호, 그리고 인공지능학과 석사과정(이한빈, 김진범, 강준형), 소프트웨어학과 석사과정 김민하, 소프트웨어학과 학부과정(김민하, 홍동희, 신새별), 교신저자 우사이먼교수가 참여하였습니다. “VFP290K: A Large-Scale Benchmark Dataset for Vision-based Fallen Person Detection”에서는 쓰러진 사람을 이상 행동으로 정의하며, 이상 행동 탐지 모델 훈련에 필요한 대규모 데이터셋을 제안하였습니다. 기존 데이터셋의 문제점(특정 상황에 국한된 촬영, 단일 연기자 구성, 환경적 요소 제외, 적은 데이터 수량 등)을 해결하기 위해, 연구팀은 학교 근교를 포함한 길거리, 공원 및 건물 내부 등 49개의 장소에서 131장면을 실제 CCTV 환경을 재현하여 촬영하였습니다. 총 294,714장의 프레임으로 구성된 VFP290K 데이터셋은 광범위한 실험을 통해 기존 데이터셋 보다 데이터의 다양성과 일반화의 우수성을 증명하였으며, 2020년 진행된 인공지능 그랜드 챌린지 대회에서 1단계 1위 및 2단계 3위의 우수한 성적을 보임으로써, VFP290K 데이터셋의 유효성을 입증하였습니다. 논문 #1 요약 및 링크 VFP290K: A Large-Scale Benchmark Dataset for Vision-based Fallen Person Detection Jaeju An*, Jeongho Kim*, Hanbeen Lee, Jinbeom Kim, Junhyung Kang, Minha Kim, Saebyeol Shin, Minha Kim, Donghee Hong, Simon S. Woo Neural Information Processing System (NeurIPS) 2021 Datasets and Benchmarks Track 요약: Detection of fallen persons due to, for example, health problems, violence, or accidents, is a critical challenge. Accordingly, detection of these anomalous events is of paramount importance for a number of applications, including but not limited to CCTV surveillance, security, and health care. Given that many detection systems rely on a comprehensive dataset comprising fallen person images collected under diverse environments and in various situations is crucial. However, existing datasets are limited to only specific environmental conditions and lack diversity. To address the above challenges and help researchers develop more robust detection systems, we create a novel, large-scale dataset for the detection of fallen persons composed of fallen person images collected in various real-world scenarios, with the support of the South Korean government. Our Vision-based Fallen Person (VFP290K) dataset consists of 294,714 frames of fallen persons extracted from 178 videos, including 131 scenes in 49 locations. We empirically demonstrate the effectiveness of the features through extensive experiments analyzing the performance shift based on object detection models. In addition, we evaluate our VFP290K dataset with properly divided versions of our dataset by measuring the performance of fallen person detecting systems. We ranked first in the first round of the anomalous behavior recognition track of AI Grand Challenge 2020, South Korea, using our VFP290K dataset, which can be found here. Our achievement implies the usefulness of our dataset for research on fallen person detection, which can further extend to other applications, such as intelligent CCTV or monitoring systems. The data and more up-to-date information have been provided at our VFP290K site. 논문 #2: “FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset” (제1저자 Hasam Khalid, 박사과정 Shahroz Tariq, 석사과정 김민하, 교신저자 우사이먼 (이상 소프트웨어학과)) “FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset”에서는 딥페이크 비디오뿐만 아니라 립싱크 된 오디오를 포함하는 새로운 딥페이크 데이터셋을 제안하였습니다. 기존 딥페이크 데이터셋이 유니모달(Unimodal)에 근거한 단일 딥페이크 데이터셋이라는 한계를 해결하기 위해, 연구팀은 최근 가장 인기 있는 딥페이크 생성 방법과 오디오 생성 방법을 사용해 거의 완벽하게 립싱크 된 멀티모달(Multimodal) 딥페이크 데이터셋을 제작하였습니다. FakeAVCeleb은 인종적 편향성을 제거하기 위해 네 인종(백인, 흑인, 동부 아시아, 남부 아시아)의 비디오를 사용했습니다. 유니모달, 앙상블 추론 및 멀티모달 환경에서 다양한 최신 방법을 사용해 광범위한 실험을 진행했으며, 멀티모달 오디오-비디오 딥페이크 데이터셋의 유용성을 입증하였습니다. 논문 #2 링크 및 요약 FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset Hasam Khalid, Shahroz Tariq, Minha Kim, Simon S. Woo Neural Information Processing System (NeurIPS) 2021 Datasets and Benchmarks Track 요약: While significant advancements have been made in the generation of deepfakes using deep learning technologies, its misuse is a well-known issue now. Deepfakes can cause severe security and privacy issues as they can be used to impersonate a person's identity in a video by replacing his/her face with another person's face. Recently, a new problem of generating synthesized human voice of a person is emerging, where AI-based deep learning models can synthesize any person's voice requiring just a few seconds of audio. With the emerging threat of impersonation attacks using deepfake audios and videos, a new generation of deepfake detectors is needed to focus on both video and audio collectively. A large amount of good quality datasets is typically required to capture the real-world scenarios to develop a competent deepfake detector. Existing deepfake datasets either contain deepfake videos or audios, which are racially biased as well. Hence, there is a crucial need for creating a good video as well as an audio deepfake dataset, which can be used to detect audio and video deepfake simultaneously. To fill this gap, we propose a novel Audio-Video Deepfake dataset (FakeAVCeleb) that contains not only deepfake videos but also respective synthesized lip-synced fake audios. We generate this dataset using the current most popular deepfake generation methods. We selected real YouTube videos of celebrities with four racial backgrounds (Caucasian, Black, East Asian, and South Asian) to develop a more realistic multimodal dataset that addresses racial bias, and further help develop multimodal deepfake detectors. We performed several experiments using state-of-the-art detection methods to evaluate our deepfake dataset and demonstrate the challenges and usefulness of our multimodal Audio-Video deepfake dataset. 위 논문들은 성균관대학교 소프트웨어학과와 인공지능학과 학생들의 협업과 노력으로 완성되었으며, 성균관대학교에서 독자적으로 추진한 연구로 본교 소프트웨어학과/인공지능학과의 우수성을 입증하였습니다.
-
- 작성일 2021-10-21
- 조회수 1214
-

- [연구] 엄영익 교수 연구실, 박종규 박사과정 SOSP 2021 국제학술대회 한국기관 최초 논문 게재
- 분산컴퓨팅연구실의 박종규 박사과정(지도교수 엄영익)이 ACM Symposium on Operating Systems Principles (SOSP) 2021에 “FragPicker: A New Defragmentation Tool for Modern Storage Devices” (저자: 박종규, 엄영익) 논문을 게재하였다. 본 논문은 기존 파일 시스템 단편화 제거 기법의 고질적인 문제점인 추가적인 쓰기 발생과 높은 소모 시간을 해결하기 위해 최신 스토리지 디바이스의 내부 특성을 고려한 새로운 단편화 제거 기법을 제안하는 논문이다. ACM SOSP는 격년으로 개최되는 운영체제 분야 최상위 학술대회로, 이번 SOSP 2021은 총 348편의 논문 중 54편(채택율 15.5%)의 논문이 채택되었다. 특히 본 건은 SOSP 학회 54년 역사상 한국 기관 최초의 논문이라는 데에 의미가 있다. [논문 정보] FragPicker: A New Defragmentation Tool for Modern Storage Devices Jonggyu Park and Young Ik Eom The 28th ACM Symposium on Operating Systems Principles (SOSP 2021) Abstract: File fragmentation has been widely studied for several decades because it negatively influences various I/O activities. To eliminate fragmentation, most defragmentation tools migrate the entire content of files into a new area. Unfortunately, such methods inevitably generate a large amount of I/Os in the process of data migration. For this reason, the conventional tools (i) cause defragmentation to be time-consuming, (ii) significantly degrade the performance of co-running applications, and (iii) even curtail the lifetime of modern storage devices. Consequently, the current usage of defragmentation is very limited although it is necessary. Our extensive experiments discover that, unlike HDDs, the performance degradation of modern storage devices incurred by fragmentation mainly stems from request splitting, where a single I/O request is split into multiple ones. With this insight, we propose a new defragmentation tool, FragPicker, to minimize the amount of I/Os induced by defragmentation, while significantly improving I/O performance. FragPicker analyzes the I/O activities of applications and migrates only those pieces of data that are crucial to the I/O performance, in order to mitigate the aforementioned problems of existing tools. Experimental results demonstrate that FragPicker efficiently reduces the amount of I/Os for defragmentation while achieving a similar level of performance improvement to the conventional defragmentation schemes.
-
- 작성일 2021-10-01
- 조회수 1700
-
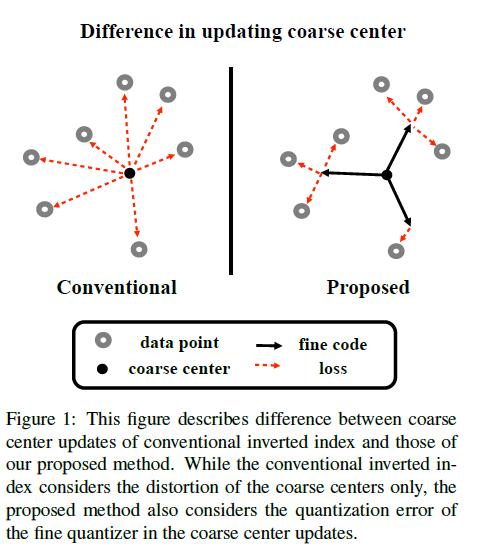
- [연구] 허재필 교수 연구실, ICCV 2021 국제학술대회 논문 2편 게재 승인 (노해찬 박사과정, 김태호 석박통합과정, 주원영 석사과정)
- 비주얼컴퓨팅연구실(지도교수: 허재필)의 논문 2편이 컴퓨터 비전 및 인공지능 분야의 Top-tier 학술대회인 IEEE/CVF International Conference on Computer Vision (ICCV) 2021 에 게재 승인되었습니다: 논문 #1: “Product Quantizer Aware Inverted Index for Scalable Nearest Neighbor Search” (인공지능학과 박사과정 노해찬 학우, 인공지능학과 석박통합과정 김태호 학우) 논문 #2: “Collaborative Learning with Disentangled Features for Zero-shot Domain Adaptation” (인공지능학과 석사과정 주원영 학우) “Product Quantizer Aware Inverted Index for Scalable Nearest Neighbor Search” 에서는 대용량 데이터 베이스에 대한 최근접 이웃 근사(Nearest Neighbor Approximation) 기술에 사용되는 역색인 (Inverted Indexing) 구조의 새로운 학습 방법을 제시하였습니다. 기존의 기술들은 탐색 속도의 복잡도를 줄이기 위한 역색인 구조와 속도 및 메모리 사용량을 줄이기 위한 손실 압축 기법을 동시에 사용하지만 각각의 기법은 독립적으로 학습되었습니다. 본 연구에서는 이 두 가지 기법을 공동 최적화 (Joint Optimization)를 통해 압축 기법의 왜곡 (Distortion) 을 줄이는 학습 방법을 제안하여 대용량 데이터 베이스에 대한 최근접 이웃 근사 기술 분야에서 가장 높은 성능을 달성하였습니다. “Collaborative Learning with Disentangled Features for Zero-shot Domain Adaptation” 연구에서는 전이학습의 한 분야인 Zero-shot Domain Adaptation (ZSDA) 을 위한 새로운 프레임워크를 제시하였습니다. ZSDA는 타겟 도메인의 특정 클래스에 대한 데이터가 존재하지 않을 때, 다른 클래스들의 도메인 변화 (Domain Shift) 를 포착하여 도메인 적응을 시도하는 기술입니다. 제안하는 모델에서는 이미지에서 도메인 특징점과 의미론적 (Semantic) 특징점을 추출한 뒤, 두 특징점간의 협력적 학습과정 (Collaborative Learning) 을 통해 클래스를 예측하도록 설계하였습니다. 제안된 모델은 현재 ZSDA 분야에서 가장 높은 성능을 달성하였으며, 추후 Zero-shot Learning 및 도메인 적응 연구에 큰 도움이 될 것입니다. [논문 #1 정보] Product Quantizer Aware Inverted Index for Scalable Nearest Neighbor Search Haechan Noh, Taeho Kim, and Jae-Pil Heo IEEE/CVF International Conference on Computer Vision (ICCV), 2021 Abstract: The inverted index is one of the most commonly used structures for non-exhaustive nearest neighbor search on large-scale datasets. It allows a significant factor of acceleration by a reduced number of distance computations with only a small fraction of the database. In particular, the inverted index enables the product quantization (PQ) to learn their codewords in the residual vector space. The quantization error of the PQ can be substantially improved in such combination since the residual vector space is much more quantization-friendly thanks to their compact distribution compared to the original data. In this paper, we first raise an unremarked but crucial question; why the inverted index and the product quantizer are optimized separately even though they are closely related? For instance, changes on the inverted index distort the whole residual vector space. To address the raised question, we suggest a joint optimization of the coarse and fine quantizers by substituting the original objective of the coarse quantizer to end-to-end quantization distortion. Moreover, our method is generic and applicable to different combinations of coarse and fine quantizers such as inverted multi-index and optimized PQ. [논문 #2 정보] Collaborative Learning with Disentangled Features for Zero-shot Domain Adaptation Won Young Jhoo, and Jae-Pil Heo IEEE/CVF International Conference on Computer Vision (ICCV), 2021 Abstract: Typical domain adaptation techniques aim to transfer the knowledge learned from a label-rich source domain to a label-scarce target domain in the same label space. However, it is often hard to get even the unlabeled target domain data of a task of interest. In such a case, we can capture the domain shift between the source domain and target domain from an unseen task and transfer it to the task of interest, which is known as zero-shot domain adaptation (ZSDA). Most of existing state-of-the-art methods for ZSDA attempted to generate target domain data. However, training such generative models causes significant computational overhead and is hardly optimized. In this paper, we propose a novel ZSDA method that learns a task-agnostic domain shift by collaborative training of domain-invariant semantic features and task-invariant domain features via adversarial learning. Meanwhile, the spatial attention map is learned from disentangled feature representations to selectively emphasize the domain-specific salient parts of the domain-invariant features. Experimental results show that our ZSDA method achieves state-of-the-art performance on several benchmarks.
-
- 작성일 2021-08-30
- 조회수 1337
-

- [연구] 우사이먼성일 교수 연구실(DASH Lab)의 전소원 석사과정 연구원, 김형식교수 연구실의 이길희 석사과정 연구원 2021 KDD Workshop on Programming Language Processing (PLP 2021) Best Paper 수상
- DASH 연구실의 소프트웨어학과 전소원 학생(소프트웨어학과 석사과정: 제1저자), 이길희 학생 (전기전자컴퓨터공학과 석사과정: 제 2 저자), 김형식 교수 (소프트웨어학과), 우사이먼성일 교수(교신저자)의 “SmartConDetect: Highly Accurate Smart Contract Code Vulnerability Detection Mechanism using BERT” 논문이 2021 KDD Workshop on Programming Language Processing (PLP 2021) (http://plpworkshop.com/)에서 Best Paper Award로 선정되었습니다. 본 연구에서는 이더리움에서 가장 많이 사용되는 언어인 솔리디티로 작성된 스마트 컨트랙트의 보안 취약점을 탐지하는 SmartConDetect를 제안합니다. 이더리움을 포함한 다수의 블록체인 플랫폼에서는 거래를 트랜잭션으로 정의하고, 실행하고 저장하는 프로그램인 스마트 컨트랙트를 지원합니다. 그러나, 안전한 스마트 컨트랙트를 개발하는 것은 쉽지 않으며, 스마트 컨트랙트의 보안 취약점은 서비스 제공자 혹은 사용자에게 금전적 피해를 야기할 수 있습니다. SmartConDetect는 스마트 컨트랙트 취약점 정적 분석 툴로, 스마트 컨트랙트의 코드를 함수 단위로 나누어 추출하고, 사전 학습된 BERT 모델을 통해 코드 패턴을 학습시킵니다. 본 모델의 성능을 평가하기 위하여 10,000개의 실제 스마트 컨트랙트 코드를 수집하였습니다. 이를 최신 모델과 비교한 결과, 본 모델은 90.9%의 F1-score를 달성하며 높은 정확도를 달성하였습니다. 논문명: “SmartConDetect: Highly Accurate Smart Contract Code Vulnerability Detection Mechanism using BERT”, 2021 KDD Workshop on Programming Language Processing (PLP 2021) 초록: Many popular blockchain platforms support smart contracts, which are the programs executed, and stored as transactions on their blockchain protocols and execution environments. However, it is not easy to develop secure smart contracts since smart contracts are programs that can often have security vulnerabilities, which may lead to severe financial loss to service providers or users. Therefore, it is critical to detect security vulnerabilities in smart contracts. In this paper, we propose SmartConDetect to detect security vulnerabilities in smart contracts written in Solidity. SmartConDetect is designed as a static analysis tool to extract code fragments from smart contracts in Solidity and further detect vulnerable code patterns using a pre-trained BERT model. To show the feasibility of SmartConDetect, we evaluate the performance of our approach with 10,000 real-world smart contracts collected from the Ethereum blockchain platform. Our experimental results demonstrate that SmartConDetect outperforms all state-of-the-art methods.
-
- 작성일 2021-08-23
- 조회수 1098
-

- [연구] 고영중 교수 자연어처리연구실, CIKM 2021 국제 학술대회 논문 4편 게재 승인
- 고영중 교수 자연어처리연구실, CIKM 2021 국제 학술대회 논문 4편 게재 승인 지도교수: 고영중 교수 자연어처리연구실 김보성 연구원, 최혜원 석사과정, 손동철 석사과정, 유하은 석사과정(이상 소프트웨어학과), 김명준 석사과정(인공지능학과)의 논문 4편이 인공지능 및 정보검색 분야의 top-tier 국제 학술대회인 CIKM (Conference on Information and Knowledge Management) 2021에 최종 논문 게재가 승인되어 11월에 발표될 예정입니다. 1. Bosung Kim, Hyewon Choi, Haeun Yu and Youngjoong Ko, "Query Reformulation for Descriptive Queries of Jargon Words Using a Knowledge Graph based on a Dictionary.", Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM 2021), November 2021. 본 연구에서는 전문 용어 검색을 위해 사전을 활용한 그래프 기반 질의 변형 시스템을 제안합니다. 서술형 질의가 주어졌을 때, 제안 시스템은 표제어와 사전 설명의 쌍으로 구성된 그래프를 통해 이에 해당하는 전문 용어를 예측합니다. 이 과정에서 그래프 신경망과 고속 그래프 검색 모델을 활용하여 검색의 정확성과 효율성을 개선했습니다. 두 개의 데이터셋을 이용한 실험 결과, 제안 방법이 서술형 질의를 전문 용어로 효과적으로 재구성할 수 있을 뿐만 아니라 여러 프레임워크에서 검색 성능을 향상시킬 수 있음을 보였습니다. 2. Meoungjun Kim and Youngjoong Ko, "Self-supervised Fine-tuning for Efficient Passage Re-ranking.", Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM 2021), November 2021. 본 연구에서는 마스킹 언어 모델(MLM) 학습을 이용한 새로운 미세 조정 기법으로 문서 랭킹 성능을 개선했습니다. 제안 모델은 랭킹 성능을 올리는 동시에 적은 데이터를 효율적으로 활용하는 데이터 증강 효과를 보였습니다. 이러한 접근 방식은 고비용의 레이블 데이터에 의존하지 않는 자기주도 학습을 정보검색에 적용했다는 의의가 있습니다. 또한, BM25 알고리즘을 활용하여 문서를 구성하는 단어의 중요도를 계산, 학습에 반영했습니다. MS MARCO Re-ranking 리더보드 데이터셋으로 실험한 결과, 우리 모델은 단일 모델로서는 가장 높은 MRR@10 성능을 얻었습니다. 3. Dongcheol Son and Youngjoong Ko, "Self-Supervised Learning based on Sentiment Analysis with Word Weight Calculation.", Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM 2021), November 2021. 감정 분석 성능을 개선하기 위해서는 도메인 정보를 학습하는 것이 중요합니다. 하지만 이를 위해서는 고비용인 대규모 학습 데이터를 확보해야 합니다. 본 연구에서는 적은 양의 데이터를 이용해 도메인 정보를 효율적으로 학습하고 감정 분석 성능을 개선할 수 있는 새로운 학습 기법을 제안합니다. 우리는 감정 분석 과제에서 단어의 중요도를 계산하고 미세 조정 성능을 개선하기 위해 마스킹 언어 모델(MLM) 학습을 사용했습니다. 감정 분석 분야의 데이터셋 네 종류를 이용한 실험 결과, 제안 모델은 이전 결과를 모두 앞서는 성능을 보였습니다. 4. Hyewon Choi and Youngjoong Ko, "Using Topic Modeling and Adversarial Neural Networks for Fake News Video Detection.", Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM 2021), November 2021. 본 연구에서는 적대적 학습과 토픽 모델을 활용하여 유튜브의 가짜 뉴스 영상을 구별할 수 있는 탐지 시스템을 제안합니다. 제안 모델에서는 영상의 제목, 설명, 댓글을 이용하여 토픽 분포를 추론하고, 제목/설명과 댓글 간 분포가 어떻게 차이 나는지를 식별합니다. 또한, 영상의 주제를 판단하는데 도움이 되는 자질을 추출하기 위해 적대적 신경망을 학습시킵니다. 우리 모델은 자세 분석에서 주제의 변화를 효율적으로 탐지할 수 있으며, 다양한 주제에서 적용이 가능합니다. 연구 결과, 가짜 뉴스 영상 탐지 분야의 기존 연구보다 더 높은 F1 스코어 성능을 얻었습니다. 고영중 교수: yjko@skku.edu, 자연어처리연구실: nlp.skku.edu; nlplab.skku.edu
-
- 작성일 2021-08-18
- 조회수 1402
-
- [연구] 우사이먼성일 교수 연구실(DASH Lab), Tariq Shahroz 박사과정 연구원,김민하 석사과정 연구원 ACMMM 2021 논문 게재 승인
- DASH 연구실 소프트웨어학과 김민하(석사과정연구원)와 Tariq Shahroz(박사과정연구원), 우사이먼성일(교신저자)의 “CoReD: Generalizing Fake Media Detection with Continual Representation using Distillation” 논문이 멀티미디어 분야에서 세계 최고 수준의 학술대회인 ACMMM (ACM Multimedia, BK IF=4) 2021년에 최종 논문 개재가 승인되었고 2021년 10월 중국 청두에서 발표될 예정입니다. 본 연구에서는 최근 사회적으로 큰 이슈로 대두되고 있는 딥페이크 동영상을 탐지하는 방법을 제안하며, 이는 이전 딥페이크 생성기법 뿐만 아니라 새로운 생성기법에서도 효율적으로 탐지 가능한 딥러닝 기반 알고리즘(Continual Learning, Knowledge Distillation, Representation Learning)을 기반으로 구성되었습니다. 최근에 딥페이크나 합성 얼굴 이미지 같은 가짜 미디어를 높은 정확도로 감지할 수 있는 방법들이 등장하고 있는 반면에, 새로운 딥페이크 생성기법들 또한 다양해지고 있습니다. 이에 따라 다양한 딥페이크 생성기법들을 탐지 가능한 대응책이 필요한 상황입니다. 하지만 기존의 딥페이크 탐지 기법들은 각 생성기법마다 대량의 학습 데이터셋이 요구되며, 이는 현실적으로 제약이 많으며 학습시간도 매우 오래 소요됩니다. 이러한 문제를 해결하기 위해서 각 생성 방법에 대한 일반적인 탐지를 위해 전이학습을 진행하며, 전이학습 방법은 모델의 지식 망각(Knowledge Forgetting)을 방지하기 위해서 이전 학습에 사용된 데이터셋의 일부가 필요합니다. 하지만 이전 학습 데이터셋을 소지하고 있는 것은 보안 측면에서 문제가 되고 영구적으로 보존하는 것은 현실적으로 어려움이 존재합니다. 따라서, 본 연구에선 소스 생성기법 없이도 기존 딥페이크 생성기법의 탐지 성능은 유지함과 동시에 새로운 딥페이크 생성기법의 탐지 성능을 향상시키기 위해서, 지식증류기법과 표현학습기법 기반의 연속학습(Continual Learning) 알고리즘 CoReD(Continual Representation using Distillation)를 개발하였습니다. 본 논문에선 세 번의 연속학습 결과를 각 태스크 별로 나누어 소스 생성기법과 타겟 생성기법에 대한 탐지 성능을 비교하였습니다. 그 결과, CoReD 알고리즘을 적용했을 때 비교 모델들과 비교하여 소스 생성기법에서 탐지 성능을 최대한 유지하면서, 타겟 생성기법에 대해서는 효과적인 성능 향상을 보여주었습니다.
-
- 작성일 2021-07-16
- 조회수 1345
-
- [연구] 성균관대학교 박은일‧한진영 교수팀, AI기반 가짜뉴스 탐지 세계 경진대회 2위
- 성균관대학교(총장 신동렬)는 인공지능융합학과 박은일‧한진영 교수 연구팀(정다혜 석박통합과정)과 이 연구실에서 창업한 스타트업 라온데이터(김지나, 윤지우 AI Scientist, 대표: 최성)로 이루어진 공동 연구진이 세계적 자연어처리 학회인 NAACL과 SocialNLP가 지난 5월 1일부터 6월 10일까지 개최한 Fake-EmoReact 2021(가짜뉴스 전파 탐지)에 참가해 2위를 차지했다고 15일 밝혔다. 올해로 2회째를 맞이한 본 대회는 소셜미디어 가짜 뉴스 탐지 모델 개발을 목표로 F1-score로 성능을 평가하는 것으로, 올해는 총 24개 팀이 참가해 그중 5개 팀이 순위에 이름을 올렸다. 연구진은 93.90%의 F1-Score를 보인 Team Yao에 이어 84.59%의 F1-Score를 달성했다. 연구진은 “다른 팀들과 달리 경량화된 기계학습 기법만을 활용하여 우수한 수준의 가짜뉴스 전파 탐지율을 보일 수 있었다”면서 “조기에 정보 전파 차단이 필요한 가짜뉴스 대응에 실제적인 도움이 될 것”이라고 밝혔다. 박은일 교수는 “가짜 뉴스에 대한 대응은 빠른 시간 아래 해당 정보를 확인하고 조기에 전파를 차단하는 것이 핵심이다. 이에 따라 복잡한 심층신경망을 활용하는 것보다 경량화된 기계학습 기법을 통해 선제적 대처까지 소요되는 시간을 단축시키는 것이 주요 쟁점으로 부각되고 있다”고 대회 참가 의의를 밝혔다. 본교-라온데이터 팀은 과학기술정보통신부와 정보통신기획평가원에서 지원하는 ICT혁신인재4.0양성사업을 바탕으로 본 대회에 처음 참가해 2위의 성적을 거두는 쾌거를 달성했으며, 향후 대회에서 활용한 경량화 기계학습 기술을 사업화하기 위한 노력을 진행할 계획이다. 출처 : 한국강사신문(http://www.lecturernews.com) 기사 본문: https://www.lecturernews.com/news/articleView.html?idxno=69584
-
- 작성일 2021-07-06
- 조회수 1133
-

- [연구] 컴퓨터시스템 분야 최상위 학회인 OSDI’21에 Embedded Software 연구실 한규화 박사졸업생 (지도교수 신동군)의 “ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone” 논문 등재
- 컴퓨터시스템 분야 최상위 학회인 OSDI’21에 Embedded Software 연구실 한규화 박사졸업생 (지도교수 신동군)의 “ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone” 논문 등재 USENIX Symposium on Operating Systems Design and Implementation (OSDI) 2021에 임베디드 소프트웨어 연구실의 한규화 박사졸업생(지도교수 신동군)의 논문이 채택되었다. “ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone” (저자: 한규화, 곽현호, 신동군, 황주영) 라는 제목으로 한규화 박사가 성균관대 재학시절 연구한 결과를 발표한 논문이다. 본 연구는 최근 new storage interface로 각광받고 있는 NVMe ZNS를 개선한 ZNS+ 구조를 제안한 논문이다. USENIX OSDI는 컴퓨터시스템 분야 최상위 flagship 학회로 매회 약 30편의 논문이 채택되며 이번 OSDI 2021은 총 165편의 논문 중 31편(채택율 18.8%)의 논문이 채택되었다. OSDI는 MapReduce (2004, 12,000 citations), Tensorflow (2016, 13,000 citations) 등의 논문과 같이 혁신적인 기술이 발표된 conference이다. OSDI학회가 열린 이후 국내 대학 주저자 논문은 2020년까지 5편밖에 없었으며, 성균관대학교 소속 저자의 논문이 채택된 것은 이번이 최초이다. [논문 정보] ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone Kyuhwa Han , Hyunho Gwak, Dongkun Shin, and Joo-Young Hwang USENIX Symposium on Operating System Design and Implementation, 2021 Abstract: The NVMe zoned namespace (ZNS) is emerging as a new storage interface, where the logical address space is divided into fixed-sized zones, and each zone must be written sequentially for flash-memory-friendly access. Owing to the sequential write-only zone scheme of the ZNS, the log-structured file system (LFS) is required to access ZNS solid-state drives (SSDs). Although SSDs can be simplified under the current ZNS interface, its counterpart LFS must bear segment compaction overhead. To resolve the problem, we propose a new LFS-aware ZNS interface, called ZNS+, where the host can offload block copy operations to the SSD to accelerate segment compaction. The ZNS+ also allows each zone to be overwritten with sparse sequential write requests, which enables the LFS to use threaded logging-based block reclamation instead of segment compaction. We also propose two file system techniques for ZNS+-aware LFS. The copyback-aware block allocation considers different copy costs at different copy paths within the SSD. The hybrid segment recycling selects a proper block reclaiming method between segment compaction and threaded logging based on their costs. The proposed ZNS+ and ZNS+-aware LFS reduce the segment recycling overhead of LFS without harming the benefit of ZNS. We evaluated the effectiveness of the proposed techniques using an SSD emulator and a real prototype SSD. The file system performance of the proposed ZNS+ storage system was 1.33–2.91 times better than that of the normal ZNS-based storage system.
-
- 작성일 2021-05-18
- 조회수 1710
-

- [연구] 컴퓨터시스템 연구실 소프트웨어학과 김종석 학생(박사과정, 지도교수 서의성)의 "Z-Journal: Scalable Per-Core Journaling" 논문 발표
- 컴퓨터시스템 연구실 소프트웨어학과 김종석 학생(박사과정, 지도교수 서의성)의 "Z-Journal: Scalable Per-Core Journaling" 논문이 USENIX Annual Technical Conference 2021 학술대회(MS Academic 기준 OS 분야 2위)에서 발표될 예정입니다. 본 연구는 SSD의 성능이 계속해서 좋아지고 있지만, 여러 스레드가 동시에 쓰기를 수행하는 경우 파일시스템의 저널 계층에서 쓰기가 일렬로 모아져야 하는 현상으로 인해 실제 쓰기 성능이 개선되지 못하는 문제를 다루었습니다. 제안하는 해결책은 각 코어마다 독립적인 저널을 두고 이들 사이의 일관성을 유지할 수 있는 일관성 유지 모델을 제시하여, 최대 40배 이상의 쓰기 성능 향상을 통해 고성능 SSD 성능을 최대한 활용할 수 있음을 확인하였습니다. [논문 정보] Z-Journal: Scalable Per-Core Journaling Jongseok Kim, Cassiano Campes, Jooyoung Hwang, Jinkyu Jeong, and Euiseong Seo USENIX Annual Technical Conference, 2021 Abstract: File system journaling critically limits the scalability of a file system because all simultaneous write operations coming from multiple threads must be serialized to be written to the journal area. Although a few scalable journaling approaches have been proposed, they required the radical redesign of file systems, or tackled only a part of the scalability bottlenecks. Per-core journaling, in which a core has its own journal stack, can clearly provide scalability. However, it requires a journal coherence mechanism because two or more cores can write to a shared file system block, so write order on the shared block must be preserved across multiple journals. In this paper, we propose a novel scalable per-core journal design. The proposed design allows a core to commit independently to other cores. The journal transactions involved in shared blocks are linked together through order-preserving transaction chaining to form a transaction order graph. The ordering constraints later will be imposed during the checkpoint process. Because the proposed design is self-contained in the journal layer and does not rely on the file system, its implementation, Z-journal, can easily replace JBD2, the generic journal layer. Our evaluation with FxMark, Sysbench and Filebench running on the ext4 file system in an 80-core server showed that it outperformed the current JBD2 by up to approx. 4000 %.
-
- 작성일 2021-05-13
- 조회수 1247
-

- [연구] [실시간 컴퓨팅 연구실] IEEE RTAS 2021 국제 저명 학술대회 논문 발표
- 실시간 컴퓨팅 연구실(지도교수:이진규)에서는 실시간 시스템 분야의 저명 국제 학술대회인 IEEE RTAS (Real-Time and Embedded Technology and Applications Symposium) 2021에 아래의 논문을 발표할 예정입니다. [논문] "ML for RT: Priority Assignment Using Machine Learning" 본 논문에서는 Real-Time Systems 분야의 난제인 Priority Assignment 문제를 Machine Learning을 통해 해결하며 ML for RT라는 새로운 연구분야를 제시하였습니다. 본 연구는 이진규 교수의 2020년 연구년 동안 University of Michigan의 Prof. Kang G. Shin과의 공동 연구를 통해 수행되었습니다. 본 논문은 실시간 컴퓨팅 연구실의 이승훈 석사과정 학생(제1저자)과 이진규 교수(교신저자)가 주저자로 참여하였으며, 인천대학교 백형부 교수, 성균관대 소프트웨어학과 우홍욱 교수, University of Michigan의 Kang G. Shin 교수가 공동저자로 참여하였습니다. 논문 다운로드: https://rtclskku.github.io/website/papers/IC202104LBW.pdf IEEE RTAS: http://2021.rtas.org 실시간 컴퓨팅 연구실: https://rtclskku.github.io/website/
-
- 작성일 2021-05-13
- 조회수 1081