 발전기금
발전기금







[연구] 이지형 교수 연구실, ACL 2023 논문 3편 게재 승인
- 소프트웨어융합대학
- 조회수1705
- 2023-05-08


정보 및 지능 시스템 연구실(지도교수: 이지형)의 논문 3편이 세계 최고 권위의 자연어처리 학술대회 (BK IF=4) “The 61st Annual Meeting of the Association for Computational Linguistics (ACL’23)”에 게재 승인되었습니다.
논문 #1: “DIP: Dead code Insertion based Black-box Attack for Programming Language Model”, ACL 2023
(인공지능학과 석박통합과정 나철원, 소프트웨어학과 박사과정 최윤석)
논문 #2: “BLOCSUM: Block Scope-based Source Code Summarization via Shared Block Representation”, Findings of ACL 2023
(소프트웨어학과 박사과정 최윤석, 인공지능학과 석사과정 김효준)
논문 #3: “CodePrompt: Task-Agnostic Prefix Tuning for Program and Language Generation”, Findings of ACL 2023
(소프트웨어학과 박사과정 최윤석)
(논문 #1)
“DIP: Dead code Insertion based Black-box Attack for Programming Language Model” 논문에서는 소스코드를 처리하는 매우 큰 사전학습모델(Large-scale pre-trained models)에 대한 적대적 공격(Adversarial Attack) 방법을 제안합니다. 기존 공격방법인 변수명을 변경하는 Sampling 기반의 방법론은 매우 많은 시도와 낮은 공격 성공률로 비효율적이며, 특히 소스코드의 특징인 컴파일 가능성을 완전히 보존하지 못하는 문제를 제기하였습니다. 이를 해결하기 위해, 소스코드에 영향을 미치지 않는 Dead code를 삽입하는 방법론을 채택하였습니다. 언어를 처리하는 대부분의 사전학습 모델은 Attention mechanism을 갖는 트랜스포머 기반 구조이기 때문에, 적대적 공격의 효율성을 높이기 위하여 어텐션 점수(Attention score)를 활용합니다. 제안된 방법은 3가지 사전학습 모델에 각 3가지 데이터를 미세조정(fine-tuning)한 총 9가지 타겟 모델에 대하여 매우 우수한 공격 성능을 보입니다.
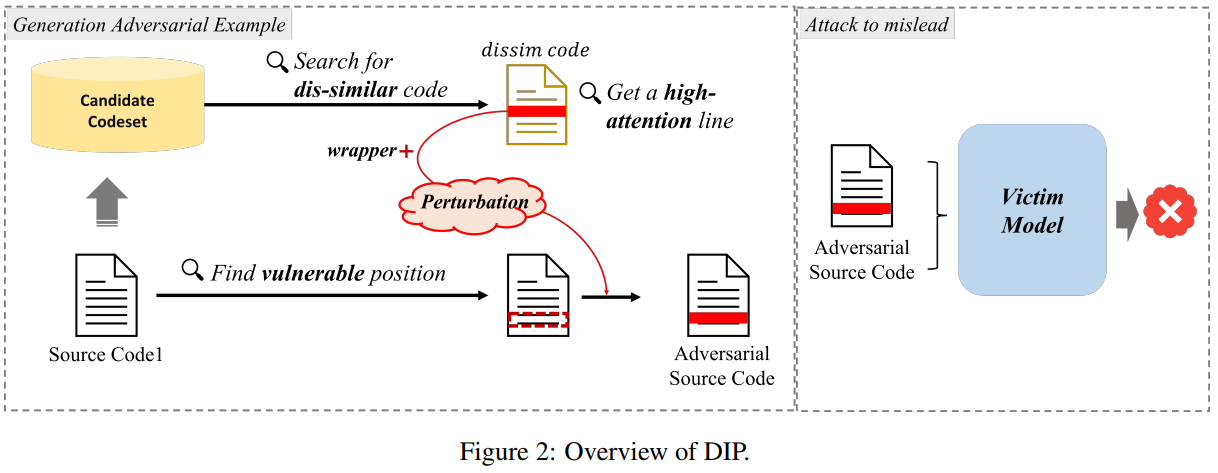 [Abstract] Automatic processing of source code, such as code clone detection and software vulnerability detection, is very helpful to software engineers. Large pre-trained Programming Language (PL) models (such as CodeBERT, GraphCodeBERT, CodeT5, etc.), show very powerful performance on these tasks. However, these PL models are vulnerable to adversarial examples that are generated with slight perturbation. Unlike natural language, an adversarial example of code must be semantic-preserving and compilable. Due to the requirements, it is hard to directly apply the existing attack methods for natural language models. In this paper, we propose DIP (Dead code Insertion based Black-box Attack for Programming Language Model), a high-performance and efficient black-box attack method to generate adversarial examples using dead code insertion. We evaluate our proposed method on 9 victim downstream-task large code models. Our method outperforms the state-of-the-art black-box attack in both attack efficiency and attack quality, while generated adversarial examples are compiled preserving semantic functionality.
[Abstract] Automatic processing of source code, such as code clone detection and software vulnerability detection, is very helpful to software engineers. Large pre-trained Programming Language (PL) models (such as CodeBERT, GraphCodeBERT, CodeT5, etc.), show very powerful performance on these tasks. However, these PL models are vulnerable to adversarial examples that are generated with slight perturbation. Unlike natural language, an adversarial example of code must be semantic-preserving and compilable. Due to the requirements, it is hard to directly apply the existing attack methods for natural language models. In this paper, we propose DIP (Dead code Insertion based Black-box Attack for Programming Language Model), a high-performance and efficient black-box attack method to generate adversarial examples using dead code insertion. We evaluate our proposed method on 9 victim downstream-task large code models. Our method outperforms the state-of-the-art black-box attack in both attack efficiency and attack quality, while generated adversarial examples are compiled preserving semantic functionality.
(논문 #2)
“BLOCSUM: Block Scope-based Source Code Summarization via Shared Block Representation” 논문에서는 소스코드를 개발자가 한눈에 이해할 수 있는 주석 형태의 자연어로 요약해주는 방법을 제안합니다. 양질의 요약문을 생성하기 위하여, 소스코드 블록의 다양한 구조를 표현함으로써 블록 범위 정보를 활용하는 공유 블록 표현(shared block representation)을 사용합니다. 소스 코드의 기본 구조 요소인 코드 블록을 활용하여 두 가지 방법을 설계했습니다. 첫 번째 방법인 공유 블록 위치 임베딩(position embedding)은 코드 블록의 구조를 효과적으로 나타내고 코드와 AST 인코더 간의 상관관계를 합치는 데 사용됩니다. 또한, 소스 코드의 블록 및 전역 종속성과 같은 풍부한 정보를 학습하기 위해 간단하면서도 효과적인 AST 변형을 재구성했습니다. 실험 결과, 제안방안의 우수성을 입증하고 코드에서 블록 범위 정보의 중요성을 확인했습니다.
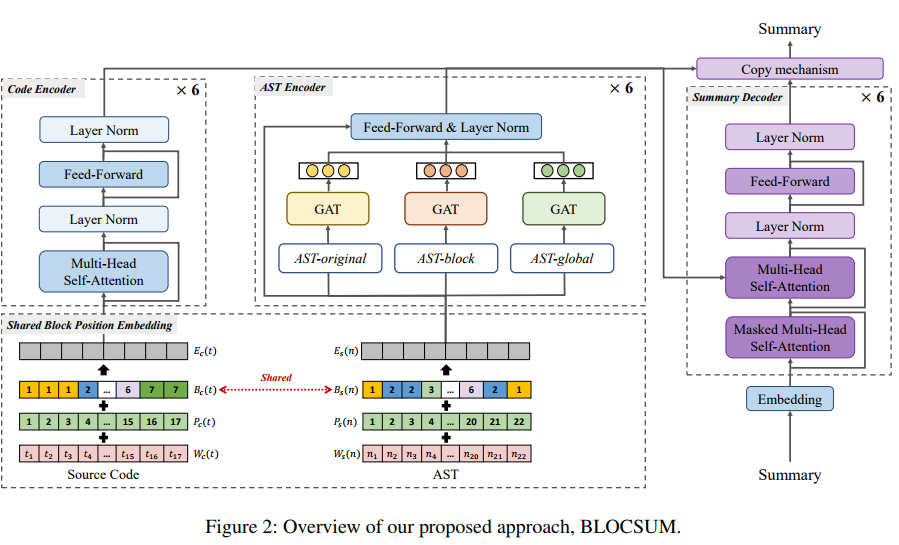
[Abstract] Code summarization, which aims to automatically generate natural language descriptions from source code, has become an essential task in software development for better program understanding. Abstract Syntax Tree (AST), which represents the syntax structure of the source code, is helpful when utilized together with the sequence of code tokens to improve the quality of code summaries. Recent works on code summarization attempted to capture the sequential and structural information of the source code, but they considered less the property that source code consists of multiple code blocks. In this paper, we propose BLOCSUM, BLOck scope-based source Code SUMmarization via shared block representation that utilizes block-scope information by representing various structures of the code block. We propose a shared block position embedding to effectively represent the structure of code blocks and merge both code and AST. Furthermore, we develop variant ASTs to learn rich information such as block and global dependencies of the source code. To prove our approach, we perform experiments on two real-world datasets, the Java dataset and the Python dataset. We demonstrate the effectiveness of BLOCSUM through various experiments, including ablation studies and a human evaluation.
(논문 #3)
“CodePrompt: Task-Agnostic Prefix Tuning for Program and Language Generation” 연구에서는 프로그램 및 언어 생성 작업을 위한 작업에 구애받지 않는(Task-agnostic) 프롬프트 튜닝 방법인 CodePrompt를 제안합니다. CodePrompt는 프로그램 및 언어를 위한 사전학습모델(Pre-train Models)의 사전 훈련 및 미세 조정 사이의 간극을 메우기 위해 입력 종속 프롬프트 템플릿을 결합하고, 사전학습모델의 매개 변수(parameters)를 효율적으로 업데이트하기 위해 말뭉치 특정 접두사 튜닝을 사용합니다. 또한, 제한된 접두사 길이에 대한 보다 풍부한 접두사 단어 정보를 제공하기 위한 다중 단어 접두사 초기화 방법을 제안했습니다. 제안 방법은 전체 데이터와 저자원 환경 뿐만 아니라 cross-domain 환경에서도 3가지 프로그램 및 언어 생성 작업(Program and Language Generation)에서 효과적임을 입증했습니다.
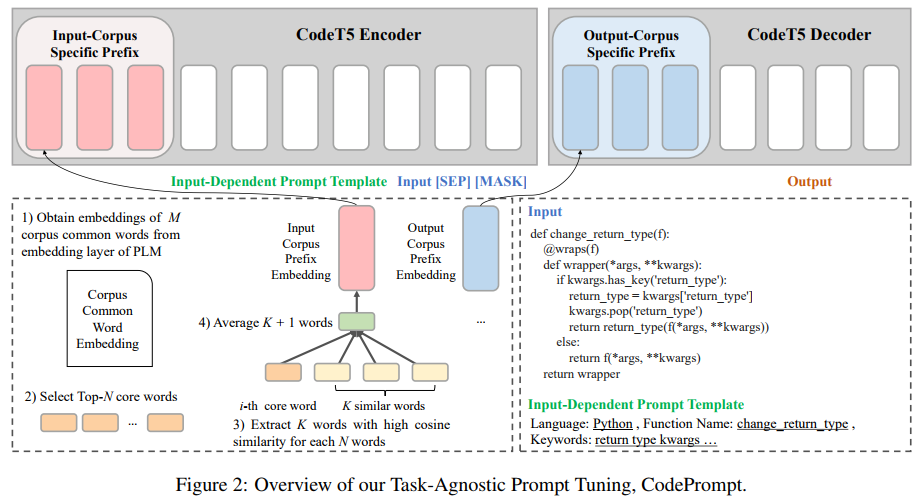
[Abstract] In order to solve the inefficient parameter update and storage issues of fine-tuning in Natural Language Generation (NLG) tasks, prompt-tuning methods have emerged as lightweight alternatives. Furthermore, efforts to reduce the gap between pre-training and fine-tuning have shown successful results in low resource settings. As large Pre-trained Language Models (PLMs) for Program and Language Generation (PLG) tasks are constantly being developed, prompt tuning methods are necessary for the tasks. However, due to the gap between pre-train and fine-tuning different from PLMs for natural language, a prompt tuning method that reflects the traits of PLM for program language is needed. In this paper, we propose a Task-Agnostic prompt tuning method for the PLG tasks, CodePrompt, that combines Input-Dependent Prompt Template (to bridge the gap between pre-training and fine-tuning of PLMs for program and language) and Corpus-Specific Prefix Tuning (to efficiently update the parameters of PLMs for program and language). Also, we propose a method to provide more rich prefix word information for limited prefix lengths. We prove that our method is effective in three PLG tasks, not only in the full-data setting, but also in the low-resource setting and cross domain setting.