 발전기금
발전기금








-

- [연구] 이지형 교수 연구실, SIGIR 2023 국제 학술대회 게재 승인
- 정보 및 지능 시스템 연구(지도교수: 이지형)의 양희윤(인공지능학과 석사과정), 최윤석(소프트웨어학과 박사과정), 김가형(인공지능학과 석사과정)의 “LOAM: Improving Long-tail Session-based Recommendation via Niche Walk Augmentation and Tail Session Mixup” 논문이 인공지능 및 정보검색 분야의 Top-tier 국제학술대회 (BK21 CS IF=4)인 SIGIR(The 46th International ACM SIGIR Conference on Research and Development in Information Retrieval) 2023에 최종 논문 게재가 승인되어 7월에 발표될 예정입니다. 본 연구에서는 추천 시스템 연구 분야 중 하나인 세션 기반 추천 시스템에서 데이터셋의 롱테일 분포로 인해 발생하는 롱테일 샘플의 추천 성능 저하 문제를 해결하기 위해 두 가지 증강기법을 제안합니다. 데이터셋의 특성인 순차성과 함께 등장하는 아이템(Sequential, item co-occurrence)등을 고려하여 기존의 학습 샘플들과 유사하면서도 다양성이 있는 증강샘플을 생성하기 위해 세션들로 이루어진 그래프를 순회하는 입력 데이터 증강 기법, NWA(Niche Walk Augmentation)를 제안합니다. 또한, 모델의 다양한 아이템 예측과 일반화(generalization)를 위해 세션의 특성(representation)을 추출한 뒤에 mixup 기반의 증강을 한 번 더 진행하였습니다. 실험 결과, 기존 제안되었던 세션 기반 추천 모델에 증강 기법을 함께 사용했을 때, 전체 샘플에 추천 정확도 저하를 최소화하면서 다양성을 향상시켰고, 롱테일 샘플에 대해 향상된 정확도와 다양성을 달성하였습니다. [논문] Heeyoon Yang, YunSeok Choi, Gahyung Kim, and Jee-Hyong Lee. “ LOAM: Improving Long-tail Session-based Recommendation via Niche Walk Augmentation and Tail Session Mixup”, In Proceedings of 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2023), July 2023. [Abstract] Session-based recommendation aims to predict the user’s next action based on anonymous sessions without using side information. Most of the real-world session datasets are sparse and have long-tail item distribution. Although long-tail item recommendation plays a crucial role in improving user satisfaction, only a few methods have been proposed to take the long-tail session recommendation into consideration. Previous works in handling data sparsity problems are mostly limited to self-supervised learning techniques with heuristic augmentation which can ruin the original characteristic of session datasets, sequential and co-occurrences, and make noisier short sessions by dropping items and cropping sequences. We propose a novel method, LOAM, improving LOng-tail session-based recommendation via niche walk Augmentation and tail session Mixup, that alleviates popularity bias and enhances long-tail recommendation performance. LOAM consists of two modules, Niche Walk Augmentation (NWA) and Tail Session Mixup (TSM). NWA can generate synthetic sessions considering long-tail distribution which are likely to be found in original datasets, unlike previous heuristic methods, and expose a recommender model to various item transitions with global information. This improves the item coverage of recommendations. TSM makes the model more generalized and robust by interpolating sessions at the representation level. It encourages the recommender system to predict niche items with more diversity and relevance. We conduct extensive experiments with four real-world datasets and verify that our methods greatly improve tail performance while balancing overall performance. 이지형 | john@skku.edu | 정보및지능시스템 Lab | http://iislab.skku.ac.kr/
-
- 작성일 2023-04-24
- 조회수 816
-

- [연구] 박호건 교수 연구실(기계학습, 데이터마이닝 연구실)의 추천 시스템 연구The Web Conference (WWW) 2023 논문 게재 승인
- 박호건 교수 연구실(기계학습, 데이터마이닝 연구실)의 추천 시스템 연구The Web Conference (WWW) 2023 논문 게재 승인. LearnData Lab(기계학습/데이터마이닝) 연구실(지도교수: 박호건, https://learndatalab.github.io)의정희수학생(석사과정)과박호건교수(교신저자)가제출한“Dual Policy Learning for Aggregation Optimization in Graph Neural Network-based Recommender Systems”논문이웹/데이터마이닝분야최우수학회 The Web Conference(WWW) 2023 (https://www2023.thewebconf.org) (BK IF=4)에게재승인되었고, 2023년 5월미국텍사스에서발표될예정입니다. 본논문은대부분의최신추천시스템의근간이되는그래프신경망(Graph neural networks; GNN)기반딥러닝모델에서사용가능한강화학습기반성능개선학습방법을제안합니다. 기존GNN 기반추천시스템은멀리떨어진이웃의정보를집계하여사용자와항목간의복잡한고차원적연결성을포착하는장점이있지만, 사용자와추천상품의이질적인특성으로인해성능향상에한계가있었습니다. 본논문에서는추천시스템을위한새로운강화학습기반메시지전달프레임워크인 DPAO(Dual Policy learning framework for Aggregation Optimization)를제안하며, 이중정책학습을사용하여사용자및상품에대한고차연결을적응적으로결정합니다. 제안한프레임워크는 Amazon, Yelp 포함 6개의실제상품추천데이터세트에서평가하였습니다. 그결과본논문이제안한프레임워크가최근발표된 GNN기반추천시스템모델을크게향상시켜, 대표적인추천시스템평가지표인nDCG와 Recall에서각각최대 63.7%와 42.9%까지향상시키는것으로나타났습니다. 구현코드와논문은본연구실홈페이지(https://learndatalab.github.io)에서확인할수있습니다. [논문정보] Heesoo Jung, Sangpil Kim, Hogun Park. Dual Policy Learning for Aggregation Optimization in Recommender Systems, In Proceedings of the ACM 32nd Web Conference: WWW 2023, Austin, USA, 2023. [Abstract] Graph Neural Networks (GNNs) provide powerful representations for recommendation tasks. GNN-based recommendation systems capture the complex high-order connectivity between users and items by aggregating information from distant neighbors and can improve the performance of recommender systems. Recently, Knowledge Graphs (KGs) have also been incorporated into the user-item interaction graph to provide more abundant contextual information; they are exploited to address cold-start problems and enable more explainable aggregation in GNN-based recommender systems (GNN-Rs). However, due to the heterogeneous nature of users and items, developing an effective aggregation strategy that works across multiple GNN-Rs, such as LightGCN and KGAT, remains a challenge. In this paper, we propose a novel reinforcement learning-based message passing framework for recommender systems, which we call DPAO (Dual Policy learning framework for Aggregation Optimization). This framework adaptively determines high-order connectivity to aggregate users and items using dual policy learning. Dual policy learning leverages two Deep-Q-Network models to exploit the user- and item-aware feedback from a GNN-R and boost the performance of the target GNN-R. Our proposed framework was evaluated with both non-KG-based and KG-based GNN-R models on six real-world datasets, and their results show that our proposed framework significantly enhances the recent base model, improving nDCG and Recall by up to 63.7% and 42.9%, respectively.
-
- 작성일 2023-02-23
- 조회수 1318
-

- [연구] 고영중 교수 자연어처리연구실, WSDM 2023 국제 학술대회 논문 게재 승인
- 고영중 교수 자연어처리연구실, WSDM 2023 국제 학술대회 논문 게재 승인 자연어처리연구실 박선영 석사과정(인공지능학과), 최규리, 유하은 석사과정(소프트웨어학과)의 “Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution” 논문이 웹 정보 검색 및 데이터 마이닝 분야의 top-tier 국제 학술대회(BK21 CS IF=3)인 WSDM (The 16th ACM International Conference on Web Search and Data Mining) 2023에 최종 논문 게재가 승인되어 2월에 발표될 예정입니다. 본 연구에서는 자연어 이해 태스크 중 하나인 상호 참조 해결로 언어 모델이 학습한 성 고정관념(stereotype)과 편향성(skew)을 완화하고 분석합니다. 사전학습 언어모델은 사전학습 과정에서 언어 이해 능력을 학습할 뿐만 아니라 대용량 코퍼스에 내재된 고정관념과 편향성 역시 학습합니다. 언어모델의 성 편견을 완화하고자 하는 기존 방법들은 편향성 문제 해결에 초점을 맞추고, 고정관념 학습 문제를 해결하지 못하거나 기존 사전학습 언어모델의 언어 이해 능력을 저하시키는 문제 등이 있었습니다. 본 논문에서는 이를 해결하기 위해 고정관념 중화(stereotype neutralization) 기법과 탄력적 변수 강화(elastic weight consolidation) 기법을 제시합니다. 대명사 참조 데이터셋을 이용한 실험 결과, 제안 기법이 사전학습 언어 모델의 성 고정관념과 편향성 문제를 효과적으로 해결한 것을 확인할 수 있었습니다. [논문] Sunyoung Park, Kyuri Choi, Haeun Yu, Youngjoong Ko, “Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution.”, Proceedings of the 16th ACM International Conference on Web Search and Data Mining (WSDM 2022), February 2023. Abstract: Leveraging pre-trained language models (PLMs) as initializers for efficient transfer learning has become a universal approach for text-related tasks. However, the models not only learn the language understanding abilities but also reproduce prejudices for certain groups in the datasets used for pre-training. Recent studies show that the biased knowledge acquired from the datasets affects the model predictions on downstream tasks. In this paper, we mitigate and analyze the gender biases in PLMs with coreference resolution, which is one of the natural language understanding (NLU) tasks. PLMs exhibit two types of gender biases: stereotype and skew. The primary causes for the biases are the imbalanced datasets with more male examples and the stereotypical examples on gender roles. While previous studies mainly focused on the skew problem, we aim to mitigate both gender biases in PLMs while maintaining the model's original linguistic capabilities. Our method employs two regularization terms, Stereotype Neutralization (SN) and Elastic Weight Consolidation (EWC). The models trained with the methods show to be neutralized and reduce the biases significantly on the WinoBias dataset compared to the public BERT. We also invented a new gender bias quantification metric called the Stereotype Quantification (SQ) score. In addition to the metrics, embedding visualizations were used to interpret how our methods have successfully debiased the models.
-
- 작성일 2023-02-22
- 조회수 1212
-

- [학생실적] 본교-국가보훈처, AI 활용하여 6·25 전쟁 영웅 사진 복원 프로젝트 진행 (우사이먼 성일 교수)
- 본교-국가보훈처, AI 활용하여 6·25 전쟁 영웅 사진 복원 프로젝트 진행 - 故김동석 대령의 장녀 가수 진미령, 흥남철수작전의 에드워드 포니 증손자 벤저민 포니 참석 - 인공지능학과/소프트웨어학과 우사이먼성일 교수, 학생 등 참여 우리 대학은 국가보훈처와 함께 빛바랜 흑백사진으로만 남아 있던 6·25전쟁 참전 영웅들의 젊은 시절을 인공지능(AI)딥러닝 기술을 활용하여 컬러사진으로 복원하는 프로젝트를 진행한다. 우리 대학과 국가보훈처는 2월 14일(화) 오후 3시 인문사회과학캠퍼스 600주년기념관에서 '불멸의 6·25전쟁 영웅, 청년으로 돌아오다' 프로젝트 업무협약식을 가졌다. 이날 협약식에는 생존 참전영웅 및 유족, 유지범 총장, 우사이먼성일 소프트웨어학과 교수와 인공지능학과(이광한, 신새별) 및 소프트웨어학과 연구진, 박민식 국가보훈처장, 신민식 자생의료재단 사회공헌위원장 등이 참석하였다. 이번 프로젝트는 6·25 전쟁 당시 찍은 국군 및 유엔군 참전용사들의 빛바랜 흑백사진을 AI 얼굴 복원기술*(GFP-GAN) 및 안면 복원(Face Restoration)을 활용하여 컬러로 복원하고 70여년 전 자유를 수호하던 영웅들의 젊은 시절 모습을 현재적 시점에서 기억하자는 취지에서 추진되었다. * GFP-GAN(Generative Facial Prior-Generative Adversarial Networks)을 이용하여 흐릿하거나 망가진 이미지를 고해상도 이미지로 복원하는 기술 ▲ AI를 활용하여 복원한 김두만 장군의 사진(사진=국가보훈처) 복원대상은 ‘미국정부가 선정한 6·25 전쟁 4대 영웅’*을 비롯해 ‘이달의 전쟁영웅’**으로 선정된 국군 및 유엔군 참전용사 중 사진이 남아있는 100여 명과 생존한 참전용사들이 장롱 속에 고이 간직하고 있던 6·25전쟁 당시 사진 등이며, 복원된 사진은 액자로 제작하여 참전용사 및 유족에게 전달된다. 또한, 국가보훈처는 컬러로 복원한 액자사진은 정전 70주년을 전후해 별도 전시하며, 사진첩으로도 발간할 예정이라고 밝혔다. * 4대 영웅: 유엔군 총사령관 더글라스 맥아더 장군 및 매슈 리지웨이 장군, 다부동 전투를 승리로 이끈 백선엽 장군, 첩보부대의 전설 김동석 대령 ** 이달의 전쟁영웅: 6·25 전쟁 60주년을 계기로 2011년 6월부터 「이달의 전쟁영웅」을 선정하여 2022년 현재까지 총 144명 선정 6·25참전 영웅들의 당시 인물사진을 국가보훈처가 성균관대에 제공하면, 본교 우사이먼성일 교수 연구팀에서는 인공지능(AI) 기술로 사진의 손상된 부분을 복원하고 딥러닝 기술을 활용해 흑백사진을 컬러로 복원하게 된다. 그리고, 박은일 교수 연구팀(https://sites.google.com/view/dxlab/)에서 데이터 처리 및 칼라링 연구를 진행할 예정이다. 한편, 프로젝트를 주도하는 우사이먼성일 교수가 국가유공자의 후손이라는 점도 주변을 놀라게 하였다. 국가유공자인 우 교수의 할아버지는 1946년 복무 수행 도중 33세의 나이로 순직해 현재는 국립묘지에 잠들어 있다. 우사이먼성일 교수는 "우연히 온 기회지만, 이번 프로젝트를 계기로 잊고 있던 할아버지의 사진을 다시 꺼내보았다"며 "할아버지와 같은 유공자 및 유가족 분들께 작은 기쁨이나마 드릴 수 있어 매우 의미 있는 프로젝트"라고 말했다. 유지범 총장은 “지금의 대한민국을 있게 해준 6·25참전영웅들의 젊은 시절이 담겨있는 사진을 복원할 수 있게 되어 매우 뜻깊다”며 “빛바랜 사진이 다시 빛을 발할 수 있도록 프로젝트에 최선을 다하겠다.”고 소감을 전했다. 박민식 국가보훈처장은 “대한민국의 자유를 위해 한 몸을 바쳤던 6·25 참전영웅들의 ‘가장 빛나던 순간’을 소환하는 프로젝트”라며, “참전영웅들이 고이 간직한 및바랜 사진 속 청년들을 복원해 그분들의 젊은 시절을 현재적 시점에서 기억하는 계기가 되길 기대한다”고 밝혔다. 한편, 자생의료재단은 이번 프로젝트를 시작으로 향후 5년간 매년 1,000여 분의 6·25참전유공자의 제복 입은 사진을 촬영하고 액자로 제작하여 선사할 예정이다. ○ 관련 언론보도 - "살아 돌아 오신 것 같다" AI로 되찾은 젊은 전쟁 영웅들의 얼굴 (중앙일보, 2023. 2. 15.)
-
- 작성일 2023-02-16
- 조회수 997
-

- [학생실적] 2022 SKKU-Fellowship 교수 13명 선정 (우사이먼 성일 교수)
- 2022 SKKU-Fellowship 교수 13명 선정 우리 대학은 '2022 SKKU-Fellowship' 교수로 유학대학 신정근 교수, 문과대학 안대회 교수, 경제대학 린슈친 교수, 정보통신대학 김병성 교수, 소프트웨어융합대학 우사이먼성일 교수, 공과대학 박호석 교수, 공과대학 장암 교수, 공과대학 김선국 교수, 생명공학대학 권대혁 교수, 의과대학 박웅양 교수, 의과대학 임호영 교수, 성균나노과학기술원 이진욱 교수, 성균융합원 신현정 교수를 선정했다. SKKU-Fellowship 제도는 우리대학이 2004년부터 수여하는 최고의 영예로, 학문 분야별 연구력수준이 세계적 표준에 안착하였거나 접근 가능성이 높은 최우수교수를 선정하여 파격적인 연구지원과 명예를 부여하는 제도이다. 특히, 2022 SKKU-Fellowship은 "인류와 미래사회를 위한 담대한 도전 Inspiring Future, Grand Challenge" 라는 대학운영방침에 기반하여 우수 전문학술저서 뿐만 아니라 저명 국제컨퍼런스, 최상위 저널과 논문, 산학협력 모델 구축(교육, 기술이전 등), 창업 등 다양한 부문에서 성과를 이룩한 교원을 대상자를 선정하였다. 시상식은 지난 2월 6일(월) 진행되었던 전체교수회의 ‘최우수 Faculty 시상식’에서 실시되었고 세대를 초월하는 Fellowship의 가치 전수를 위해 전년도 수상자인 정현석 교수가 2022 SKKU Fellowship 교수 13명 명단을 발표하였다. 대표 수상소감을 밝힌 문과대학 안대회 교수는 "인문고전정신의 정수인 저서 관련 교내에 본인 외에도 우수한 교수님들이 많으신데 대표자로 선정된 것 관련되어서 책임감이 느껴진다"며 "15년 동안 본인의 전공 관련 저서 및 등재지 등을 꾸준히 발간하면서 노력해왔는데 앞으로도 그 성과가 이어나갈 수 있도록 노력하겠다"고 소감을 밝혔다. 최우수 저널 및 논문 부문에 선정된 공과대학 장암 교수는 "Fellowship 수상이 영광이다. 개인의 성과보다는 소속 연구실 그리고 이 자리에 같이 참여해준 대학원생, 연구원생들과 함께한 성과라서 더 의미가 있다"며 "향후에도 수처리분야의 세계적 전문연구실로 발전해나가겠다"고 포부를 밝혔다. 창업 부문에 선정된 의과대학 박웅양 교수는 "우리 대학이 논문 등 학술 성과도 우수하지만 산학협력, 특히 창업 분야에서도 명성이 높은 대학이 될 수 있도록 많은 교수님들의 창업 도전 그리고 학교의 많은 관심과 지원을 요청드린다"고 말했다. 향후에도 우리 대학은 획일화된 평가에서 벗어나 교원의 다양한 성과와 가치를 발굴하여 인류사회에 공헌하는 초일류 대학으로 발전해나갈 예정이다.
-
- 작성일 2023-02-15
- 조회수 759
-

- [연구] 이상원 교수/남범석 교수 공동연구팀, VLDB 2023 국제학술대회 논문 게재 승인
- 이상원 교수/남범석 교수 공동연구팀, VLDB 2023 국제학술대회 논문 게재 승인 VLDB 연구실(지도교수: 이상원)의 안미진, 박종혁 (공동 1저자, 소프트웨어플랫폼학과 22년 8월 박사졸업) DICL 연구실 (지도교수: 남범석)의 남범석 교수가 공동연구 진행한 “NV-SQL: Boosting OLTP Performance with Non-Volatile DIMMs" 논문이 49th International Conference on Very Large Data Bases (VLDB)에 게재 승인되었습니다. VLDB는 데이터베이스 분야의 Top-tier 학술대회이며, 캐나다 밴쿠버에서 개최됩니다. 본 연구에서는 NVDIMM (Non-Volatile DIMM)을 DRAM과 같은 계층에서 쓰기 캐시로 도입하여 SSD 쓰기의 상당 부분을 흡수하는 새로운 데이터베이스 아키텍처인 NV-SQL을 제안합니다. NV-SQL은 두가지 기술적 의의를 가집니다. 첫째, 소량의 NVDIMM을 효율적으로 활용하기 위해, LSN으로 도출된 재업데이트 간격 기반 캐싱 기반 정책을 제안하였습니다. 페이지 접근 빈도 정보를 페이지 LSN으로만 도출할 수 있다는 점에서 참신합니다. 둘째, NVDIMM 캐싱 페이지가 충돌 시 페이지 작업 일관성을 위반할 수 있음을 발견하고 페이지별 업데이트 플래그를 사용하여 일치하지 않는 페이지를 감지하는 방법과 리두 로그를 사용하여 이를 수정하는 방법을 제안하였습니다. NV-SQL을 MySQL/InnoDB엔진에 구현하여, 쓰기 집약적인 OLTP 벤치마크를 활용한 성능평가를 수행한 결과, 트랜잭션 처리량 측면에서 DRAM이 더 큰 동일한 가격의 바닐라 MySQL보다 약 6.5배 더 뛰어남을 확인하였습니다. 이는 NV-SQL이 소량의 NVDIMM으로 SSD쓰기를 줄여 트랜잭션 처리량 성능을 높일 수 있음을 보여줍니다. https://vldb.org/2023/?review-board
-
- 작성일 2023-02-10
- 조회수 1126
-

- [동문] 이상원 교수 연구실 박종혁 박사 2023년도 한국외국어대학교 컴퓨터공학부 조교수 임용
- 이상원 교수 연구실 박종혁 박사 2023년도 한국외국어대학교 컴퓨터공학부 조교수 임용 VLDB 연구실(지도교수: 이상원)의 박종혁 박사가2023년도 한국외국어대학교 컴퓨터공학부 조교수로 임용되었습니다. 박종혁 박사는 성균관대학교 소프트웨어학과 3기입니다. 2013년 소프트웨어학과 입학, 2016년 동대학 소프트웨어플랫폼학과 석/박 통합과정을 거쳐 2022년 8월 컴퓨터공학 박사학위를 받았습니다. 또한, 본교 IT융합연구원 정보통신 기술 연구소에서 전문연구요원으로 복무하였습니다. 연구분야는 플래시 저장장치 및 비휘발성 메모리를 위한 데이터베이스 엔진 최적화입니다. 박종혁 박사는 이상원교수님의 지도하에 데이터베이스 분야 최우수 학술대회 3건을 발표하였고, 본교 소프트웨어학과 최초 삼성 휴먼테크 논문대상 은상을 수상하였습니다. 우수한 연구 성과를 인정받아, 2023년 한국외국어대학교 컴퓨터공학부 조교수로 만 27세의 나이로 임용되었습니다.
-
- 작성일 2023-02-10
- 조회수 915
-
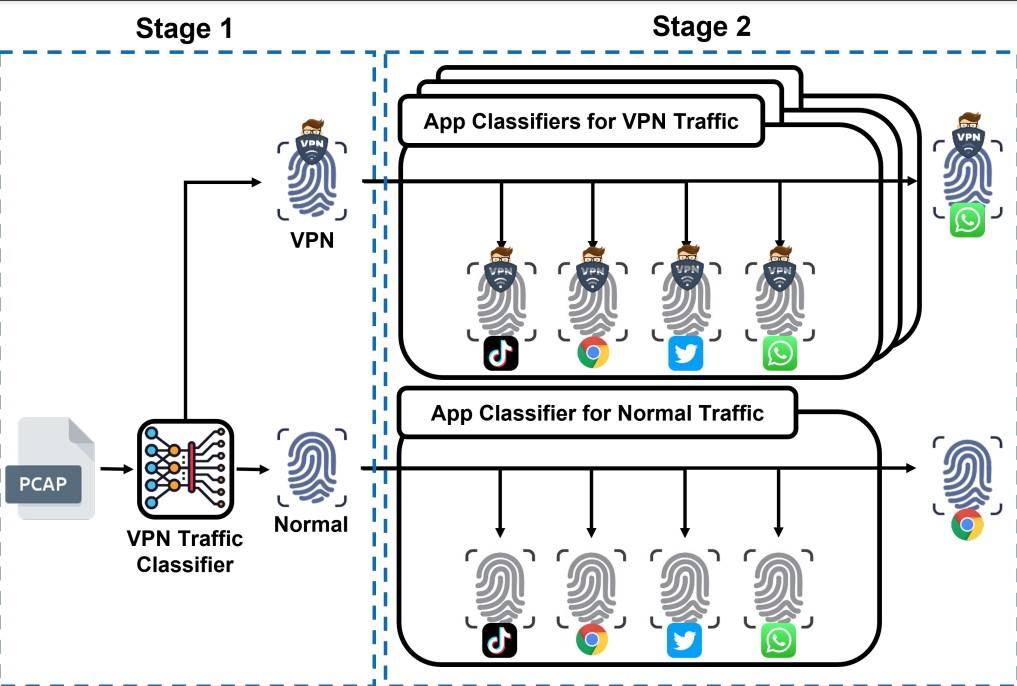
- [연구] 보안공학 연구실, The Web Conference (WWW) 2023 논문 게재 승인
- 보안공학 연구실, The Web Conference (WWW) 2023 논문 게재 승인 보안공학 연구실(지도교수: 김형식, https://seclab.skku.edu)의 오상학 학생(박사과정)과 김형식 교수(교신저자)가 진행한 “AppSniffer: Towards Robust Mobile App Fingerprinting Against VPN” 논문이 웹/데이터 마이닝 분야 최우수 학회 The Web Conference (WWW) 2023 (https://www2023.thewebconf.org) (BK IF=4)에 게재 승인되었고, 2023년 4월 미국 텍사스에서 발표될 예정입니다. 본 논문은 기존 모바일 앱 핑거프린팅 시스템들이 VPN 기술을 통해 쉽게 우회될 수 있는 한계점을 실험을 통해 제시하고, 이를 보완하기 위해 새로운 모바일 앱 핑거프린팅 시스템인 AppSniffer를 제안합니다. AppSniffer는 모바일 앱 트래픽이 VPN 환경에서 생성되었더라도 이를 분석하여 특징점을 추출하고, 앙상블 모델링을 통해 최종적으로 모바일 앱 핑거프린팅을 수행할 수 있도록 설계되었습니다. 본 논문에서는 100개의 모바일 앱 트래픽을 일반 환경과 VPN 환경에서 수집하였고, 이를 기반으로 실험을 통해 AppSniffer가 모든 환경(일반/VPN 환경)에서 모바일 앱 핑거프린팅을 수행할 수 있음을 보임으로써 VPN traffic에 robust함을 보여주었습니다. [논문 정보] Sanghak Oh, Minwook Lee, Hyunwoo Lee, Elisa Bertino, and Hyoungshick Kim. AppSniffer: Towards Robust Mobile App Fingerprinting Against VPN” In Proceedings of the ACM 32nd Web Conference: WWW 2023, Austin, USA, 2023 Abstract: Application fingerprinting is a useful data analysis technique for network administrators, marketing agencies, and security analysts. For example, an administrator can adopt application fingerprinting techniques to determine whether a user's network access is allowed. Several mobile application fingerprinting techniques (e.g., Flowprint, AppScanner, and ET-BERT) were recently introduced to identify applications using the characteristics of network traffic. However, we find that the performance of the existing mobile application fingerprinting systems significantly degrades when a virtual private network (VPN) is used. To address such a shortcoming, we propose a framework dubbed AppSniffer that uses a two-stage classification process for mobile app fingerprinting. In the first stage, we distinguish VPN traffic from normal traffic; in the second stage, we use the optimal model for each traffic type. Specifically, we propose a stacked ensemble model using Light Gradient Boosting Machine (LightGBM) and a FastAI library-based neural network model to identify applications' traffic when a VPN is used. To show the feasibility of AppSniffer, we evaluate the detection accuracy of AppSniffer for 100 popularly used Android apps. Our experimental results show that AppSniffer effectively identifies mobile applications over VPNs with F1-scores between 80.71% and 92.66% across four different VPN protocols. In contrast, the best state-of-the-art method (i.e., AppScanner) demonstrates significantly lower F1-scores between 31.69% and 48.22% in the same settings. Overall, when normal traffic and VPN traffic are mixed, AppSniffer achieves an F1-score of 88.52%, which is significantly better than AppScanner that shows an F1-score of 73.93%.
-
- 작성일 2023-01-30
- 조회수 1283
-

- [연구] 허재필 교수 연구실, AAAI 2023 논문 2편 게재 승인
- 비주얼컴퓨팅연구실(지도교수: 허재필)의 논문 2편이 인공지능 분야의 Top-tier 학술대회인 AAAI Conference on Artificial Intelligence 2023 (AAAI-23) 에 게재 승인되었습니다. 논문 #1: "Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition" (인공지능학과 박사과정 문원준, 인공지능학과 석박통합과정 성현석) 논문 #2: “Progressive Few-shot Adaption of Generative Model with Align-free Spatial Correlation” (DMC공학과 석사과정 문종보, 인공지능학과 석박통합과정 김현준, 공동1저자) "Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition" 논문에서는 비디오 데이터 취득할 때 발생하는 데이터 불균형 문제를 다루고 있습니다. 먼저, 데이터 불균형과 함께 비디오 분야에서 추가적으로 고려해야하는 문제점들을 먼저 제기하고 있는데 이는 1) 비디오 데이터에 대한 weak-supervision과 2) 기존의 비디오 데이터의 크기 때문에 사용하던 Pretrained Network가 다운 스트림 작업들에 적합하지 않다는 점입니다. 이를 보완하기 위해 해당 논문에서는 두가지 Attentive Aggregator를 도입하고, 데이터 불균형 문제를 해결하기 위해서는 데이터가 적은 클래스의 다양성을 증가시키는 변형된 외삽과 보간 기법을 제안합니다. 실험을 통해 제안된 방법이 여러 벤치마크에서 일관된 성능 향상을 가져오는 것은 물론, 새롭게 제안하는 벤치마크에서도 성능의 증가가 있음을 확인하였습니다. 추가로, 절제 연구를 통하여 데이터 불균형과 동시에 다루어야 한다고 주장한 두 가지 문제점의 대한 중요도도 실험으로 확인하였습니다. “Progressive Few-shot Adaption of Generative Model with Align-free Spatial Correlation” 논문에서는 매우 적은 수의 타겟 도메인 이미지만을 가지고 GANs 모델을 Adaptation하는 문제를 다루고 있습니다. 파인-튜닝과 같은 일반적인 방법을 사용하면 Mode-collapse에 취약하기 때문에 Source와 Target 모델이 각각 생성한 이미지들의 상대적인 거리를 유지하도록 학습하는 방법이 최근 연구되고 있지만, 1) 이미지의 전체 특징으로 거리를 측정하는 방식은 Source 모델이 갖는 세부적인 특징이 손실되고, 2) 이미지 패치단위 특징의 일관성을 유지하게 학습하는 방식은 Target 도메인의 구조적인 특성을 잃는 문제가 있습니다. 이를 보완하기 위해 해당 논문에서는 의미 있는 영역 간의 비교(예: 사람의 눈과 캐릭터의 눈 영역 비교)를 통해 Source 모델의 세부적인 특징을 보존하면서도 Target 도메인의 구조적인 특성을 반영하는 Adaptation을 목표로 1) Domain Gap을 줄여주는 Progressive Adaptation, 2) 의미 있는 영역 간의 비교를 위한 Align-free Spatial Correlation, 3) Importance Sampling 방식들을 제안하였습니다. 다양한 실험을 통해 제안한 방법이 정량적, 정성적 평가에서 우수한 성능을 나타내는 것으로 확인하였고, 특히 사람 평가에서도 좋은 결과를 보였습니다. [논문 #1 정보] Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition WonJun Moon, Hyun Seok Seong, and Jae-Pil Heo Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), 2023 Abstract: A dramatic increase in real-world video volume with extremely diverse and emerging topics naturally forms a long-tailed video distribution in terms of their categories, and it spotlights the need for Video Long-Tailed Recognition (VLTR). In this work, we summarize the challenges in VLTR and explore how to overcome them. The challenges are: (1) it is impractical to re-train the whole model for high-quality features, (2) acquiring frame-wise labels requires extensive cost, and (3) long-tailed data triggers biased training. Yet, most existing works for VLTR unavoidably utilize image-level features extracted from pretrained models which are task-irrelevant, and learn by video-level labels. Therefore, to deal with such (1) task-irrelevant features and (2) video-level labels, we introduce two complementary learnable feature aggregators. Learnable layers in each aggregator are to produce task-relevant representations, and each aggregator is to assemble the snippet-wise knowledge into a video representative. Then, we propose Minority-Oriented Vicinity Expansion (MOVE) that explicitly leverages the class frequency into approximating the vicinity distributions to alleviate (3) biased training. By combining these solutions, our approach achieves state-of-the-art results on large-scale VideoLT and synthetically induced Imbalanced-MiniKinetics200. With VideoLT features from ResNet-50, it attains 18% and 58% relative improvements on head and tail classes over the previous state-of-the-art method, respectively. [논문 #2 정보] Progressive Few-shot Adaption of Generative Model with Align-free Spatial Correlation Jongbo Moon*, Hyunjun Kim*, and Jae-Pil Heo (*: equal contribution) Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), 2023 Abstract: In few-shot generative model adaptation, the model for target domain is prone to the mode-collapse. Recent studies attempted to mitigate the problem by matching the relationship among samples generated from the same latent codes in source and target domains. The objective is further extended to image patch-level to transfer the spatial correlation within an instance. However, the patch-level approach assumes the consistency of spatial structure between source and target domains. For example, the positions of eyes in two domains are almost identical. Thus, it can bring visual artifacts if source and target domain images are not nicely aligned. In this paper, we propose a few-shot generative model adaptation method free from such assumption, based on a motivation that generative models are progressively adapting from the source domain to the target domain. Such progressive changes allow us to identify semantically coherent image regions between instances generated by models at a neighboring training iteration to consider the spatial correlation. We also propose an importance-based patch selection strategy to reduce the complexity of patch-level correlation matching. Our method shows the state-of-the-art few-shot domain adaptation performance in the qualitative and quantitative evaluations.
-
- 작성일 2023-01-25
- 조회수 1253
-

- [연구] 컴퓨터시스템 연구실 HPCA 2023 논문
- 제목: 컴퓨터시스템 연구실 (지도교수: 서의성) HPCA 2023 논문 컴퓨터시스템 연구실의 유준열, 김종석 박사과정과 서의성 교수는 클라우드에서 인공지능 서비스를 제공할 때, 서버, 가속장치, 그리고 인공지능 모델의 조합과 자원투입량에 따라 에너지 효율성이 크게 차이가 남을 발견하고, 이를 응용하여 기존 클라우드에서 인공지능을 서비스하는 GPU 서버가 소비하는 에너지를 20% 이상 절약할 수 있는 클라우드 플랫폼 자원 관리 기법을 개발하였습니다. 이상의 발견과 제안하는 기법은 "Know Your Enemy To Save Cloud Energy: Energy-Performance Characterization of Machine Learning Serving”이라는 제목으로 2월 25일 캐나다의 몬트리올에서 열리는 29회 IEEE International Symposium on High-Performance Computer Architecture (HPCA)에 발표될 예정입니다. HPCA는 컴퓨터 구조 및 시스템 분야에서 최고 수준의 학술대회이며, BK21+ 사업에서 가장 높은 등급(IF 4)을 인정 받고 있습니다. Abstract:The proportion of machine learning (ML) inference in modern cloud workloads is rapidly increasing, and graphic processing units (GPUs) are the most preferred computational accelerators for it. The massively parallel computing capability of GPUs is well-suited to the inference workloads but consumes more power than conventional CPUs. Therefore, GPU servers contribute significantly to the total power consumption of a data center. However, despite their heavy power consumption, GPU power management in cloud-scale has not yet been actively researched. In this paper, we reveal three findings about energy efficiency of ML inference clusters in the cloud. <1> GPUs of different architectures have comparative advantages in energy efficiency to each other for a set of ML models. <2> The energy efficiency of a GPU set may significantly vary depending on the number of active GPUs and their clock frequencies even when producing the same level of throughput. <3> The service level objective(SLO)-blind dynamic voltage and frequency scaling (DVFS) driver of commercial GPUs maintain an immoderately high clock frequency. Based on these implications, we propose a hierarchical GPU resource management approach for cloud-scale inference services. The proposed approach consists of energy-aware cluster allocation, intra-cluster node scaling, intra-node GPU scaling and GPU clock scaling schemes considering the inference service architecture hierarchy. We evaluated our approach with its prototype implementation and cloud-scale simulation. The evaluation with real-world traces showed that the proposed schemes can save up to 28.3\% of the cloud-scale energy consumption when serving five ML models with 105 servers having three different kinds of GPUs. 홈페이지: https://hpca-conf.org/2023/
-
- 작성일 2023-01-25
- 조회수 1102