[Faculty] Data Intelligence and Learning Lab (supervisor: Lee Jong-wook), SIGIR, CIKM, EMNLP 2023 Papers Published 7 Papers
- 소프트웨어융합대학
- Hit467
- 2023-12-04
The Data Intelligence and Learning (DIAL) lab has finally approved three papers for publication at SIGIR 2023, the world's most prestigious information retrieval society, and published them in Madrid, Spain, on July 23. On October 21, a total of two papers were finally approved for publication in CIKM 2023, the world's most prestigious data mining conference, and the paper was published in Birmingham, England. In addition, a total of two papers have been approved for publication in EMNLP 2023, the world's most prestigious natural language processing society, and they will present them in Singapore in December.
[List of papers]
1. 1. It’s Enough: Relaxing Diagonal Constraints in Linear Autoencoders for Recommendation (SIGIR'23)
2. 2. uCTRL: Unbiased Contrastive Representation Learning via Alignment and Uniformity for Collaborative Filtering (SIGIR'23)
3. 3. ConQueR: Contextualized Query Reduction using Search Logs (SIGIR'23)
4. Forgetting-aware Linear Bias for Attentive Knowledge Tracing (CIKM'23)
5. 5. Toward a Better Understanding of Loss Functions for Collaborative Filtering (CIKM'23)
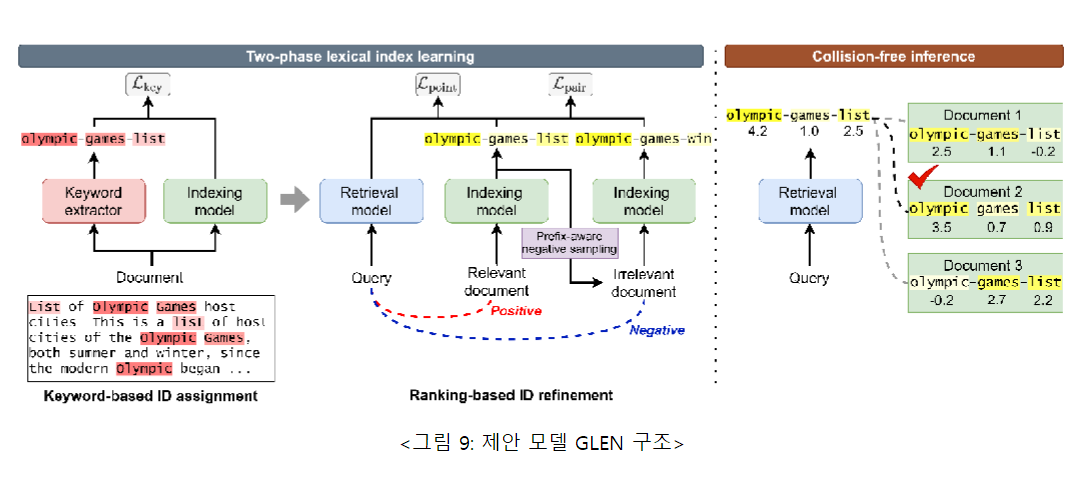
6. 6. GLEN: Generative Retrieval via Lexical Index Learning (EMNLP'23)
7. 7. It Ain't Over: A Multi-aspect Diverse Math Word Problem Dataset (EMNLP'23)
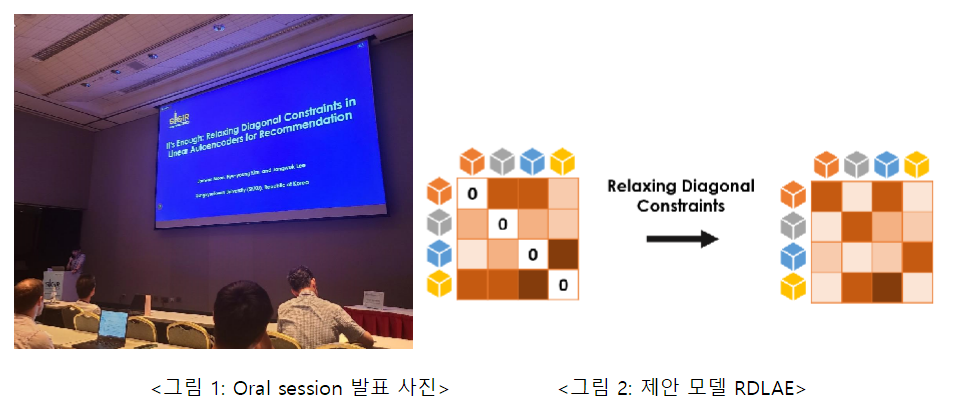
연구 1: Jaewan Moon, Hye-young Kim, and Jongwuk Lee, “It’s Enough: Relaxing Diagonal Constraints in Linear Autoencoders for Recommendation”, 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2023
This study conducts a theoretical analysis of diagonal constraints in a linear autoencoder-based recommendation system, We propose relaxed linear autocoders (RLAE) that relax diagonal constraints. The linear autoencoder model learns the weight matrix between items through L2 normalization and convex optimization with zero-diagonal constraints. This paper aims to theoretically understand the characteristics of two constraints in a linear autoencoder model. Analysis of the weight matrix using singular value decomposition (SVD) and principal component analysis (PCA) reveals that L2 normalization promotes the effectiveness of high-ranking principal components. On the other hand, we have shown that diagonal component removal constraints can reduce the effects of low-ranking principal components, leading to performance degradation of unpopular items. Inspired by these analysis results, we propose a simple yet effective linear autoencoder model, the Relaxed Denoising Linear AutoEncoder (RLAE) and the Relaxed Denoising Linear AutoEncoder (RDLAE), using diagonal inequality constraints. In addition, the proposed method of adjusting the degree of diagonal constraints provides proof that it is a generalized form of the existing linear model. Experimental results show that our model is similar or better than state-of-the-art linear and nonlinear models on six benchmark datasets. This supports theoretical insights into diagonal constraints, and we find significant performance improvements, especially in unbiased evaluation, which eliminates popularity and popularity bias. If you would like to know more about this paper, please refer to the following address.
URL: https://dial.skku.edu/blog/sigir2023_itsenough
연구 2: Jae-woong Lee, Seongmin Park, Mincheol Yoon, and Jongwuk Lee, “uCTRL: Unbiased Contrastive Representation Learning via Alignment and Uniformity for Collaborative Filtering”, 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR, short paper), 2023
This study solves the problem that when learning using implicit feedback (e.g., click, etc.) in a recommendation system, implicit feedback is mainly biased toward popular users and items, so that the representation of users and items is learned differently from the preferences of real users and items. In this study, we point out that studies removing bias from conventional recommendations do not (i) consider the widely used contrast loss function for better representation learning, and (ii) when removing bias, we complement this. In this study, we found Unbiased Conservative Representation Learning (uCTRL) First, inspired by DirectAU, a model using contrast loss functions in conventional recommendation systems, we present contrasting representation learning as two loss functions: alignment and uniformity. The alignment function makes the representations of users and items similar for user-item interactions. The uniformity function represents the distribution of each user and item equally. We find that the alignment function is biased toward the popularity of users and items, and after estimating the bias, we use it to remove the bias using inverse propensity weighting (IPW). Additionally, we have developed a new method of estimating bias by considering both users and items used in IPW. Our experimental results have shown that the proposed uCTRL outperforms the state-of-the-art deflection models on four benchmark datasets (MovieLens 1M, Gowalla, Yelp, and Yahoo! R3). If you would like to learn more about this paper, please refer to this address.
URL: https://dial.skku.edu/blog/2023_uctrl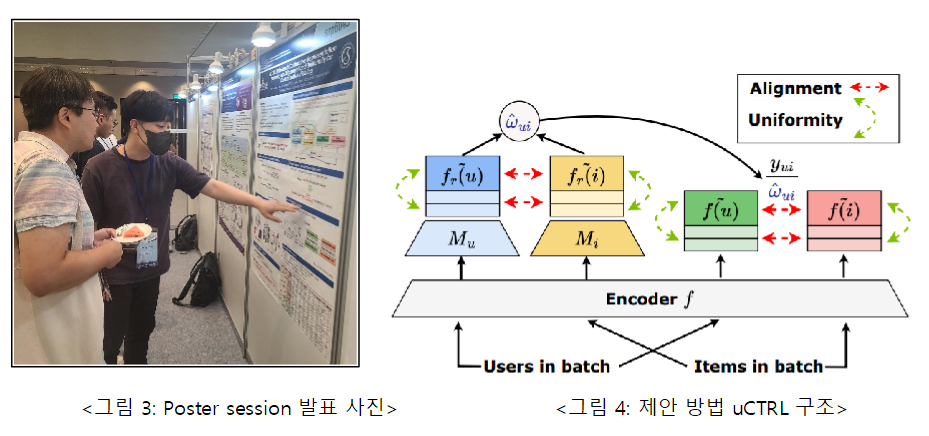 연구 3: Hye-young Kim*, Minjin Choi*, Sunkyung Lee, Eunseong Choi, Young-In Song, and Jongwuk Lee, “ConQueR: Contextualized Query Reduction using Search Logs”, 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR, short paper), 2023This study proposes a query abbreviation model using a pre-trained language model. A query abbreviation refers to a method to find the desired search result by removing unnecessary words from the query when a user enters too long a query (search word) to obtain the appropriate result to suit his or her intention. The proposed model ConQueR solves this problem from two perspectives: (i) extracting key terms and (ii) selecting sub-queries. The key term extraction method extracts key terms of an existing query at the word level, and the sub-query selection method determines at the sentence level whether the given sub-query is the correct abbreviation of the existing query. Since the two perspectives worked at different levels and had a complementary relationship, the proposed model ConQueR finally combines them to obtain the correct abbreviation. In addition, we designed to facilitate learning by introducing truncated loss learning method to handle erroneous samples that may occur frequently in search logs. Through performance experiments and satisfaction surveys on search log data collected by real search engines, we demonstrate that the proposed model effectively performed query abbreviation. If you would like to know more about this paper, please refer to the following address.
연구 3: Hye-young Kim*, Minjin Choi*, Sunkyung Lee, Eunseong Choi, Young-In Song, and Jongwuk Lee, “ConQueR: Contextualized Query Reduction using Search Logs”, 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR, short paper), 2023This study proposes a query abbreviation model using a pre-trained language model. A query abbreviation refers to a method to find the desired search result by removing unnecessary words from the query when a user enters too long a query (search word) to obtain the appropriate result to suit his or her intention. The proposed model ConQueR solves this problem from two perspectives: (i) extracting key terms and (ii) selecting sub-queries. The key term extraction method extracts key terms of an existing query at the word level, and the sub-query selection method determines at the sentence level whether the given sub-query is the correct abbreviation of the existing query. Since the two perspectives worked at different levels and had a complementary relationship, the proposed model ConQueR finally combines them to obtain the correct abbreviation. In addition, we designed to facilitate learning by introducing truncated loss learning method to handle erroneous samples that may occur frequently in search logs. Through performance experiments and satisfaction surveys on search log data collected by real search engines, we demonstrate that the proposed model effectively performed query abbreviation. If you would like to know more about this paper, please refer to the following address.
URL: https://dial.skku.edu/blog/2023_conquer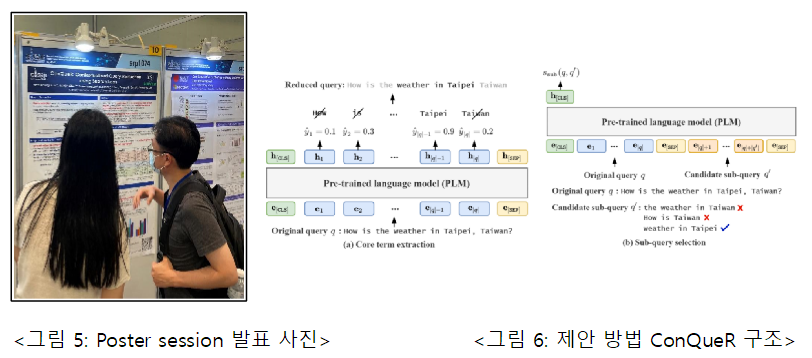 연구 4: Yoonjin Im*, Eunseong Choi*, Heejin Kook, and Jongwuk Lee, “Forgetting-aware Linear Bias for Attentive Knowledge Tracing”, The 32nd ACM International Conference on Information and Knowledge Management (CIKM, short paper), 2023Knowledge tracking models proficiency through tasks that predict correct and incorrect answers to new target problems based on learners' sequential past problem solving records. In order to accurately predict learners' proficiency, it is important to learn correlations between problems and learners' characteristics (e.g., forgetfulness behavior). Therefore, some concentration mechanism-based knowledge tracking models have modeled learners' forgetting behavior by introducing relative time interval bias instead of absolute positional embedding. This implements forgetting behavior by reducing the model's concentration as the older problem solving records at the present time point. However, existing methodologies show that the longer the problem solving record, the less effective the forgetting behavior modeling is. In this study, we determine that correlations between problems are unnecessarily involved in the calculation of conventional relative time interval biases through generalized formula analysis, and to address this, we propose Forgetting aware Linear Bias for Attentive Knowledge Tracking (FoLiBi) based on linear biases that can separate each other. The proposed methodology can easily be applied to an existing centralized mechanism-based knowledge tracking model, and despite being a simple method, we consistently improve AUC by up to 2.58% over the state-of-the-art knowledge tracking model on four benchmark datasets. To learn more about this paper, please refer to the following address.
연구 4: Yoonjin Im*, Eunseong Choi*, Heejin Kook, and Jongwuk Lee, “Forgetting-aware Linear Bias for Attentive Knowledge Tracing”, The 32nd ACM International Conference on Information and Knowledge Management (CIKM, short paper), 2023Knowledge tracking models proficiency through tasks that predict correct and incorrect answers to new target problems based on learners' sequential past problem solving records. In order to accurately predict learners' proficiency, it is important to learn correlations between problems and learners' characteristics (e.g., forgetfulness behavior). Therefore, some concentration mechanism-based knowledge tracking models have modeled learners' forgetting behavior by introducing relative time interval bias instead of absolute positional embedding. This implements forgetting behavior by reducing the model's concentration as the older problem solving records at the present time point. However, existing methodologies show that the longer the problem solving record, the less effective the forgetting behavior modeling is. In this study, we determine that correlations between problems are unnecessarily involved in the calculation of conventional relative time interval biases through generalized formula analysis, and to address this, we propose Forgetting aware Linear Bias for Attentive Knowledge Tracking (FoLiBi) based on linear biases that can separate each other. The proposed methodology can easily be applied to an existing centralized mechanism-based knowledge tracking model, and despite being a simple method, we consistently improve AUC by up to 2.58% over the state-of-the-art knowledge tracking model on four benchmark datasets. To learn more about this paper, please refer to the following address.
URL: https://dial.skku.edu/blog/2023_folibi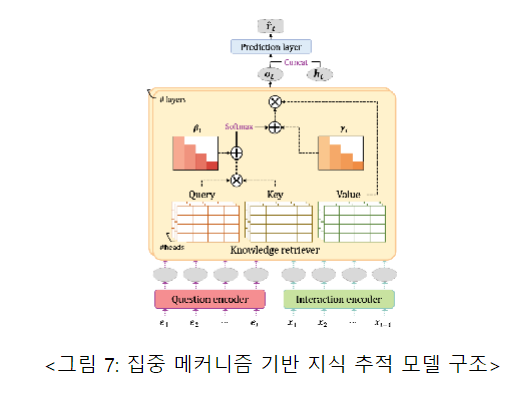 연구 5: Seongmin Park, Mincheol Yoon, Jae-woong Lee, Hogun Park, and Jongwuk Lee, “Toward a Better Understanding of Loss Functions for Collaborative Filtering”, The 32nd ACM International Conference on Information and Knowledge Management (CIKM), 2023
연구 5: Seongmin Park, Mincheol Yoon, Jae-woong Lee, Hogun Park, and Jongwuk Lee, “Toward a Better Understanding of Loss Functions for Collaborative Filtering”, The 32nd ACM International Conference on Information and Knowledge Management (CIKM), 2023
This study analyzes the formal relationship between various loss functions used in collaborative filtering, an axis of the recommendation system, and proposes a new loss function based on this relationship. Collaborative filtering is a key technology in the latest recommendation systems, and the learning process of collaborative filtering models typically consists of three components: interactive encoders, loss functions, and negative sampling. Although many previous studies have proposed a variety of collaborative filtering models to design sophisticated interaction encoders, recent studies show that a large performance improvement can be achieved simply by replacing the loss function. In this paper, we analyze the relationship between the existing loss functions and find that the existing loss functions can be interpreted as alignment and uniformity. (i) Alignment matches the user and item representation, and (ii) uniformity serves to distribute the user and item distribution. Inspired by this analysis, we propose a new Margin-aware Alignment and Weighted Uniformity (MAWU) that improves the design of alignment and uniformity by taking into account the unique patterns of the dataset. (i) Margin-aware Alignment (MA) mitigates user/item popularity bias, and (ii) Weighted Uniformity (WU) adjusts user and item uniformity to reflect the unique characteristics of the dataset. Experiments show that MF and LightGCN with MAWU are similar to or better than state-of-the-art collaborative filtering models using various loss functions on three benchmark datasets. If you would like to know more about this paper, please refer to the following address.
URL: https://dial.skku.edu/blog/2023_mawu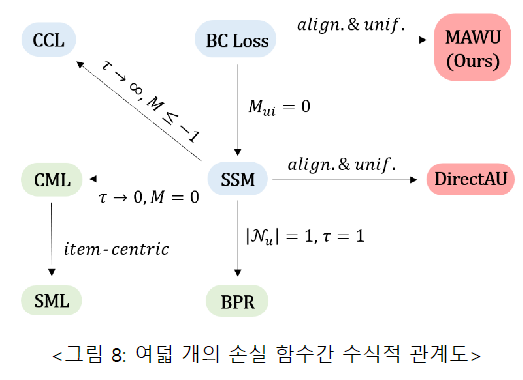 연구 6: Sunkyung Lee*, Minjin Choi*, Jongwuk Lee (* : equal contribution), “GLEN: Generative Retrieval via Lexical Index Learning”, The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 (To appear)
연구 6: Sunkyung Lee*, Minjin Choi*, Jongwuk Lee (* : equal contribution), “GLEN: Generative Retrieval via Lexical Index Learning”, The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 (To appear)
This study proposes a new generative retrieval model via LExical Index Learning (GLEN) through vocabulary index learning. Generative retrieval is a new paradigm in document retrieval that aims to generate the identifier of the relevant document directly for the query. However, existing generative search studies have two major limitations. The first is that the identifier generation in the document differs significantly from conventional natural language generation but does not take this into account. The second is a learning-inference mismatch caused by the need to rank similar documents in reasoning, although only the generation of identifiers in learning is focused. To overcome this, this study proposes a new generative search methodology that dynamically learns lexical indexes. The proposed methodology takes additional pre-learning steps to (i) generate a keyword-based fixed document identifier through a two-phase index learning strategy (two-phase flexible index learning), and (ii) to learn the dynamic document identifier through the relevance between queries and documents. Experiments demonstrate that the proposed model GLEN achieves the best or competitive performance over traditional generated or traditional search models on various benchmark datasets such as NQ320k, MS MARCO, and BEIR. The code can be found at https://github.com/skleee/GLEN . If you would like to know more about this paper, please refer to the following address.
URL: https://dial.skku.edu/blog/2023_glen
연구 7: Jiwoo Kim, Youngbin Kim, Ilwoong Baek, JinYeong Bak, Jongwuk Lee, “It Ain't Over: A Multi-aspect Diverse Math Word Problem Dataset”, The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 (To appear)
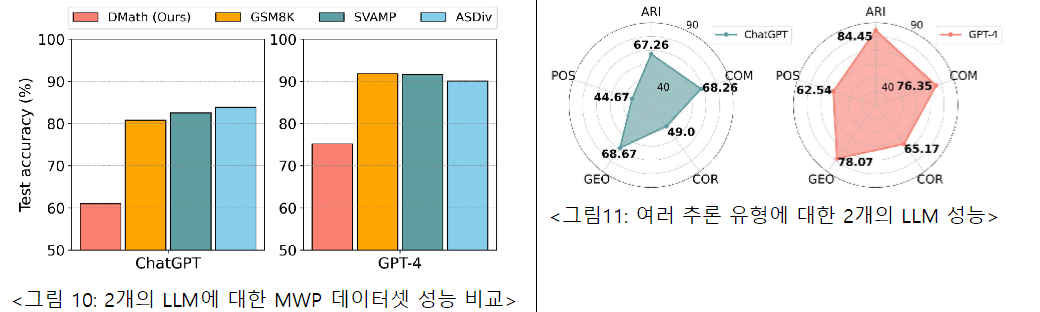
This study analyzes the mathematical reasoning ability of the Large Language Model (LLM), To improve this, we propose a new 10K dataset called Diverse Math Word Problems (DMath). Math Word Problem (MWP) tasks are complex and interesting tasks that require natural language models to have a deep understanding of natural language sentences and logical reasoning, and have been mainly used to evaluate natural language models' reasoning abilities. In recent years, the advent of the Large Language Model (LLM) has led to high performance on existing mathematical sentence problem benchmarks, and through this, LLM is known to have good mathematical reasoning ability. However, this is a result of limited benchmarks, and this paper points out the low diversity of existing benchmarks and shows that they should be increased. This paper defines a total of four diversity that a mathematical sentence problem dataset should have. These are problem types, logical usage patterns, languages, and intermediate solution forms. To define the type of reasoning, this study referred to the mathematics curriculum in the United States and Korea and defined it as arithmetic calculation, comparison, correlation, geometry, and possibility. Because previous studies have focused on arithmetic operations, little is known about what LLM produces for other types of mathematical reasoning capabilities. Experiments in this study show that LLM's reasoning ability varies greatly depending on the type of reasoning. We also pursued high diversity in vocabulary usage patterns, language, and intermediate solution processes, and these characteristics make DMath a more challenging dataset than previous studies. In addition, 43 people participated in the process of organizing and building the data, and they pursued high quality through sophisticated verification. Due to its high diversity, DMath can help examine and evaluate the different reasoning abilities of LLMs. Related data can be found at https://github.com/JiwooKimAR/dmath . If you would like to know more about this paper, please refer to the following address.
URL: https://dial.skku.edu/blog/2023_dmath